Как видит разработчик файл изображения: общая "структура файла", несмотря на разные форматы
С точки зрения пользователя файл изображения – это просто «один рисунок».\nС точки зрения разработчика он выглядит иначе: это бинарные данные, содержащие изображение, но при этом это структурированный документ, в котором описано, как эти данные интерпретировать.
В этой статье мы отложим детали конкретных форматов (JPG/PNG/WebP) и сосредоточимся только на общих структурах, которые встречаются в большинстве файлов изображений. Терминология будет минимальной, а объяснения – только по структуре.
Файл изображения – это не «пиксели», а «байтовый набор с правилами»
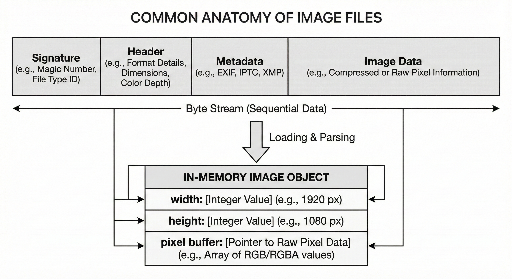
Ключевые элементы, которые обычно присутствуют в файле изображения:
- Область идентификации: указывает, к какому формату относится файл.
- Информация для интерпретации: размер, цветовое представление и т.д. – «как читать» данные.
- Собственные данные изображения: обычно хранятся в сжатом/кодированном виде.
Названия и расположение могут отличаться, но общая схема почти неизменна.
1) Файловый сигнатур: первый индикатор типа файла
Большинство файлов изображений начинаются с уникального паттерна байтов – сигнатуры. Это надёжнее расширения.
- Расширение можно изменить пользователем.
- Сигнатура же, если не соответствует формату, почти невозможно распознать.
Для разработчика тип файла определяется не по имени, а по первым байтам.
Сигнатура обычно короткая, но служит отправной точкой для чтения заголовка.
2) Заголовок: минимальная информация, необходимая для восстановления пикселей
После сигнатуры следует заголовок, содержащий данные, необходимые декодеру для восстановления пикселей.
Ключевые сведения:
- Ширина/высота: width, height
- Способ цветового представления: RGB, наличие альфа‑канала и т.д.
- Точность (битность): 8‑бит, 16‑бит и т.д.
- Метод чтения данных: наличие сжатия/кодирования и необходимые преобразования.
Важно: пиксельные данные обычно «не читаемы напрямую»; файл сначала сообщает, как их читать.
Без заголовка даже наличие данных не гарантирует корректную интерпретацию.
3) Метаданные: информация о файле, а не о самом изображении
В файле могут храниться дополнительные сведения, не обязательные для отображения изображения, но полезные в приложениях.
- Время съемки, данные камеры, ориентация (поворот)
- Информация о цветовой схеме
- Миниатюра для предпросмотра
- Информация о редакторе, авторские права и т.д.
С точки зрения разработчика:
- Метаданные может быть или не быть.
- Они могут влиять на работу (например, ориентация).
- Могут содержать проблемы безопасности/конфиденциальности (например, GPS‑данные).
Поэтому иногда нужно обрабатывать и метаданные.
4) Данные изображения: обычно хранятся в сжатом/кодированном виде
Цель файла изображения – хранить и передавать данные. Поэтому данные обычно:
- Не сжаты (редко, ограниченно): прямое хранение значений пикселей.
- Сжаты/кодированы (обычно): преобразованы для экономии места.
Ключевой момент: данные в файле редко являются прямым массивом пикселей. Их нужно декодировать, чтобы получить пиксели в памяти.
Файл оптимизирован для хранения, а буфер пикселей – для обработки.
5) «Файл» и «память» – два разных вида
Разработчик видит изображение в двух формах:
- Файл на диске – поток байтов: сигнатура + заголовок/метаданные + данные.
- Объект в памяти – структура с width/height, буфером пикселей и вспомогательной информацией.
Типичный поток обработки:
- Читаем начало файла, определяем тип (сигнатура).
- Читаем заголовок, решаем, как декодировать.
- Декодируем данные в буфер пикселей.
- После этого применяем ресайз, crop, фильтры и т.д.
Таким образом, файл изображения – это структурированные данные, а не просто набор пикселей.
Итоги: чтение файла изображения – это интерпретация структуры
Несмотря на различия форматов, общая схема для разработчика: сигнатура → заголовок → (опционально) метаданные → данные изображения. Это не просто конвенция, а проектная идея, обеспечивающая надёжную и последовательную интерпретацию.
Когда мы говорим «открыть изображение», фактически происходит:
- Определение типа по сигнатуре.
- Получение правил чтения из заголовка.
- При необходимости учёт метаданных.
- Декодирование данных в пиксели памяти.
Понимание этой структуры позволяет быстро диагностировать проблемы даже без специализированных библиотек.
Предстоящая статья
- Как
python-magicи командаfileв Linux связаны и как они определяют тип файла. - Что делают ключевые методы Pillow (PIL) –
open(),load(),verify()– и когда их использовать.
Смотрите также: