La perspective des développeurs sur les fichiers image : la structure commune des "fichiers" même si les formats diffèrent
Du point de vue d'un utilisateur, un fichier image est simplement "une image". Du point de vue d'un développeur, c'est un données binaires contenant une image et, en même temps, un document structuré indiquant comment interpréter ces données.
Dans cet article, nous mettons de côté les particularités de JPG/PNG/WebP et nous nous concentrons uniquement sur la structure commune qui apparaît dans tous les formats d'image. Nous minimisons les termes techniques et expliquons uniquement à partir de la structure.
Un fichier image n'est pas un "bloc de pixels" mais un "bloc de bytes contenant des règles"
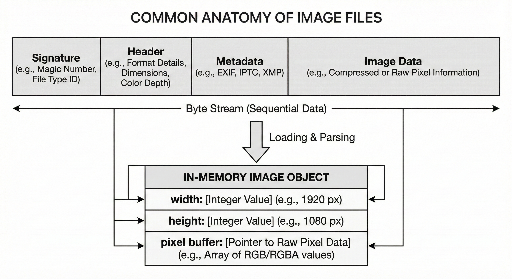
La structure de base d'un fichier image se compose généralement de trois parties :
- Zone d'identification : indique le format du fichier.
- Informations nécessaires à l'interprétation : taille, mode de couleur, etc.
- Données d'image réelles : généralement compressées ou encodées.
Les noms et l'ordre peuvent varier d'un format à l'autre, mais la trame générale reste la même.
1) Signature du fichier : la première indication de "ce que c'est"
La plupart des fichiers image commencent par un motif de bytes unique. C'est un indice plus fiable que l'extension.
- L'extension peut être modifiée librement.
- La signature en tête du fichier est difficile à deviner si le format n'est pas respecté.
Ainsi, pour un développeur, la détection du type de fichier se fait en examinant les premiers bytes, pas le nom de fichier.
Cette signature est courte (quelques bytes) mais constitue le point de départ pour décider d'ouvrir ou non le fichier.
2) Header : les informations minimales nécessaires pour reconstruire les pixels
Une fois le format identifié, on lit généralement l'en-tête. Il contient les données indispensables pour que le décodeur reconstitue les pixels.
Les informations typiques incluent :
- Largeur / hauteur : width, height
- Mode de couleur : RGB, présence d'un canal alpha, etc.
- Précision : 8 bits, 16 bits, etc.
- Méthode de lecture : compression, encodage, traitements requis.
Les données de pixels sont souvent dans un format difficile à lire directement, d'où la nécessité d'un header.
Sans header ou si celui-ci est corrompu, les données de pixels restent inutilisables.
3) Métadonnées : informations sur l'image, pas l'image elle‑même
Un fichier image peut contenir des informations supplémentaires utiles ou problématiques :
- Date de prise, infos caméra, orientation (rotation)
- Informations sur l'espace colorimétrique
- Miniature (thumbnail) pour aperçu
- Outils de création, mentions de droits d'auteur, etc.
Du point de vue du développeur, les métadonnées sont :
- Optionnelles.
- Pouvant influencer le fonctionnement (ex. orientation).
- Souvent source de problèmes de sécurité ou de confidentialité (ex. localisation).
Il ne suffit donc pas de « extraire les pixels » ; dans certains systèmes, les métadonnées doivent être traitées également.
4) Données d'image : la plupart du temps compressées ou encodées
L'objectif d'un fichier image est le stockage et la transmission. Les données d'image sont donc généralement :
- Non compressées (rare ou limité) : valeurs de pixels stockées telles quelles.
- Compressées / encodées (majorité) : format transformé pour réduire la taille.
Le contenu d'un fichier image n'est pas forcément un tableau de pixels direct. Il faut souvent le décoder pour obtenir les pixels en mémoire.
Le fichier est optimisé pour le stockage, tandis que le tampon de pixels en mémoire est optimisé pour le traitement.
5) « Fichier » vs « Mémoire » : deux apparences différentes
Même pour la même image, un développeur rencontre deux formes :
- Fichier sur disque : flux de bytes (signature + header/métadonnées + données).
- Objet en mémoire : structure contenant width/height, tampon de pixels, et éventuellement d'autres infos.
Le flux de travail typique est :
- Lire les premiers bytes pour deviner le format (signature).
- Lire l'en-tête pour déterminer la méthode de décodage.
- Décoder les données et charger les pixels en mémoire.
- Appliquer redimensionnement, découpage, filtres, etc.
Cette perspective montre qu'un "fichier image" n'est pas seulement une image, mais un données structurées interprétables.
Conclusion : lire un fichier image, c'est interpréter sa structure
Les formats varient, mais la séquence commune reste : signature → header → (optionnel) métadonnées → données d'image. Cette séquence n'est pas arbitraire ; elle est conçue pour garantir une interprétation sûre et cohérente.
Ouvrir une image implique :
- Identifier le format via la signature.
- Obtenir les règles d'interprétation via l'en-tête.
- Prendre en compte les métadonnées si nécessaire.
- Décoder les données pour obtenir les pixels en mémoire.
Connaître cette structure permet de diagnostiquer rapidement les problèmes, même sans bibliothèque spécialisée, en identifiant à quel stade l'erreur survient (identification, header, décodage).
Teaser du prochain article
- Comment
python-magicet la commandefilede Linux se rapportent‑ils, et comment ces outils déterminent le type de fichier ? - Les différences entre
open(),load(),verify()de Pillow (PIL) et quand choisir chaque méthode.
Articles connexes :