
Bonjour à tous les développeurs ! Êtes-vous en train de soupirer à cause des lourdes tâches qui ralentissent vos services web ? Lorsque vous devez interroger plusieurs bases de données, appeler des API externes et traiter des images pour chaque demande utilisateur, notre service a tendance à s'interrompre. C'est là qu'intervient notre sauveur, Celery.
Beaucoup d'entre vous ont utilisé Celery pour traiter des tâches en arrière-plan et améliorer la réactivité de leur service. Avec une simple ligne comme some_long_running_task.delay(args), ces lourdes tâches s'éloignent du thread principal et s'exécutent en arrière-plan comme par magie. Cependant, peu d'entre vous ont eu l'occasion d'explorer en profondeur la véritable nature et le fonctionnement de delay() cachés derrière cette commodité. Aujourd'hui, nous allons examiner en détail la méthode delay() et améliorer vos compétences d'utilisation de Celery.

1. Pourquoi faut-il Celery ?
Rappelons brièvement pourquoi Celery est nécessaire. Dans le développement d'applications web, nous faisons souvent face aux scénarios suivants :
- Tâches consommatrices de temps : envoi d'e-mails, traitement d'images/vidéos, calculs statistiques complexes, import/export de données massives, etc.
- Dépendance à des services externes : possibilité de délais de réponse lors des appels d'API externes.
- Pics de trafic instantanés : une multitude de requêtes arrive à court terme, ce qui peut entraîner une surcharge du serveur web.
Si ces tâches sont effectuées directement sur le thread principal qui traite les requêtes des utilisateurs, celui-ci devra attendre la fin de la tâche. Cela augmente le temps de réponse du service et finira par dégrader l'expérience utilisateur. Si les ressources du serveur sont insuffisantes ou si une tâche prend trop de temps, cela peut même mener à un délai d'attente ou un plantage du serveur.
Celery est un système de file d'attente de tâches distribuées destiné à résoudre ces problèmes. Il permet au serveur web de traiter rapidement les requêtes nécessitant une réponse immédiate, tandis que les tâches chronophages sont déléguées à Celery pour être traitées de manière asynchrone en arrière-plan, améliorant ainsi la réactivité et la stabilité du service.
2. Qu'est-ce que la méthode delay() ?
Alors, quel est exactement le rôle de la méthode delay() que nous utilisons couramment ?
La méthode delay() est le moyen le plus simple de planifier l'exécution asynchrone d'une tâche Celery.
Les fonctions définies avec le décorateur @app.task ou @shared_task ne sont plus de simples fonctions Python. Elles sont enveloppées par Celery en un objet Task spécial, et cet objet Task dispose de méthodes telles que delay() et apply_async(). Lorsque vous appelez la méthode delay(), votre code ne lance pas directement la fonction de tâche, mais compose les informations nécessaires à l'exécution de la tâche (nom de la fonction, arguments, etc.) sous forme de message et les envoie au courtier de messages (Message Broker) de Celery.
3. Le fonctionnement de delay() : le voyage derrière la magie
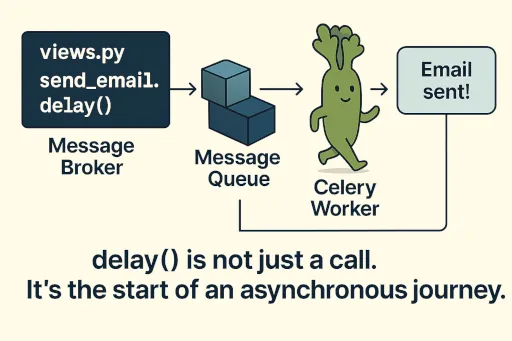
Si delay() semble être un "sort" qui permet d'exécuter des tâches asynchrones en une seule ligne, il existe en réalité un processus systématique qui se cache derrière le fonctionnement de Celery. Voici les étapes qui se produisent lors de l'appel de delay().
-
Appel de la tâche (
delay()appelé) : dans le code principal de l'application, comme une vue Django, nous appelonsmy_task_function.delay(arg1, arg2). -
Création d'un message : le client Celery (l'application Django) génère un message indiquant que la tâche
my_task_functiondoit être exécutée avec les argumentsarg1etarg2. Ce message est sérialisé au format JSON ou Pickle standard, incluant le nom de la tâche, les arguments à transmettre (args, kwargs), et d'autres métadonnées nécessaires (par exemple, l'ID de la tâche). -
Envoi au courtier de messages : le message créé est envoyé au courtier de messages de Celery. Ce courtier peut être un système de queue de messages comme Redis, RabbitMQ ou Kafka. Il stocke ce message dans une file (Queue) spécifique.
-
Réception du message par le travailleur : le travailleur (Worker) Celery est connecté au courtier de messages et effectue un polling continu ou s'abonne à une file pour recevoir les messages. Lorsqu'un nouveau message arrive dans la file, le travailleur le reçoit.
-
Désérialisation et exécution de la tâche : le travailleur désérialise le message reçu pour en extraire le nom et les arguments de la tâche. Il recherche ensuite la fonction de tâche (
my_task_function) et l'exécute de manière indépendante dans son propre processus ou thread. -
Stockage des résultats (optionnel) : lorsque l'exécution de la tâche est terminée, le résultat peut être stocké dans le backend de résultats de Celery. Ce backend peut être divers comme Redis, une base de données (Django ORM), S3, etc. Les résultats peuvent être consultés plus tard via un objet
AsyncResult. -
Réponse de la vue : pendant que tout ce processus se déroule en arrière-plan, l'application principale (par exemple, une vue Django) qui a appelé
delay()renvoie immédiatement une réponse au client dès que la tâche a été ajoutée avec succès à la file. La requête web n'est plus bloquée pendant un long moment.
Grâce à cette architecture séparée, le serveur web peut répondre rapidement aux demandes, tandis que les tâches lourdes sont déléguées aux travailleurs Celery, ce qui améliore considérablement la performance et l'évolutivité du système.
4. Exemples d'utilisation de delay()
Examinons quelques scénarios courants d'utilisation de delay().
Exemple 1 : Tâche d'envoi d'e-mail simple
# myapp/tasks.py
from celery import shared_task
import time
@shared_task
def send_email_task(recipient_email, subject, message):
print(f"Envoi de l'e-mail à {recipient_email} - Sujet : {subject}")
time.sleep(5) # Délai simulant l'envoi de l'e-mail
print(f"E-mail envoyé à {recipient_email}")
return True
# myapp/views.py
from django.http import HttpResponse
from .tasks import send_email_task
def contact_view(request):
if request.method == 'POST':
recipient = request.POST.get('email')
sub = "Merci pour votre demande."
msg = "Votre demande a été reçue avec succès."
# Exécute la tâche d'envoi d'e-mail de manière asynchrone
send_email_task.delay(recipient, sub, msg)
return HttpResponse("Votre demande a été reçue et l'e-mail sera bientôt envoyé.")
return HttpResponse("Page de contact.")
Lorsque l'utilisateur soumet le formulaire de demande, send_email_task.delay() est appelé, et la tâche d'envoi d'e-mail passe en arrière-plan. Le serveur web répond immédiatement, donc l'utilisateur n'a pas besoin d'attendre l'achèvement de l'envoi d'e-mail.
Exemple 2 : Tâche de création de miniature d'image
# myapp/tasks.py
from celery import shared_task
import os
from PIL import Image # Bibliothèque Pillow nécessaire : pip install Pillow
@shared_task
def create_thumbnail_task(image_path, size=(128, 128)):
try:
img = Image.open(image_path)
thumb_path = f"{os.path.splitext(image_path)[0]}_thumb{os.path.splitext(image_path)[1]}"
img.thumbnail(size)
img.save(thumb_path)
print(f"Miniature créée pour {image_path} à {thumb_path}")
return thumb_path
except Exception as e:
print(f"Erreur lors de la création de la miniature pour {image_path} : {e}")
raise
# myapp/views.py
from django.http import HttpResponse
from .tasks import create_thumbnail_task
def upload_image_view(request):
if request.method == 'POST' and request.FILES.get('image'):
uploaded_image = request.FILES['image']
# Enregistrer l'image à un chemin temporaire (dans les services réels, utiliser un stockage comme S3)
save_path = f"/tmp/{uploaded_image.name}"
with open(save_path, 'wb+') as destination:
for chunk in uploaded_image.chunks():
destination.write(chunk)
# Exécute la tâche de création de miniature de manière asynchrone
create_thumbnail_task.delay(save_path)
return HttpResponse("L'image est en cours de téléchargement et la miniature sera créée en arrière-plan.")
return HttpResponse("Page de téléchargement d'image.")
Les tâches gourmandes en ressources comme le téléchargement d'images peuvent également être traitées de manière asynchrone grâce à delay(), réduisant ainsi la charge sur le serveur web.
5. Avantages et limites de delay()
Avantages :
- API concise et intuitive : c'est le plus grand atout.
delay()est très pratique pour mettre directement la tâche dans la file sans options supplémentaires. - Amélioration de la réactivité : en transférant les tâches en arrière-plan sans bloquer le thread de traitement des requêtes web, il fournit une réponse rapide à l'utilisateur.
- Scalabilité : il est facile de distribuer la charge de travail et d'ajuster le nombre de travailleurs pour gérer le débit selon les besoins.
- Fiabilité : en cas d'échec de certaines tâches, cela n'affecte pas le serveur web dans son ensemble, permettant un traitement fiable grâce à des mécanismes de réessai, etc.
Limites :
- Support uniquement pour des options simples :
delay()est un moyen de base pour mettre la tâche dans la file. Vous ne pouvez pas configurer directement des options avancées telles que retarder l'exécution de la tâche à un moment spécifique, l'envoyer à une file spécifique ou définir des priorités. Pour cela, vous devez utiliserapply_async(). - Simplicité de la gestion des erreurs : l'appel
delay()ne retourne que si la tâche a été ajoutée avec succès dans la file. On ne sait pas immédiatement si la tâche a réussi ou échoué ou quel est le résultat. Pour cela, le backend de résultats et l'objetAsyncResultdoivent être utilisés.
Conclusion
Aujourd'hui, nous avons examiné en détail le fonctionnement de la méthode delay(), essentielle à Celery, ainsi que son utilisation. J'espère que vous avez compris que delay() est bien plus qu'une simple syntaxe pratique, mais plutôt la clé pour comprendre comment fonctionne le système de file d'attente de tâches distribuées de Celery.
Dans la prochaine publication, nous aborderons en profondeur la méthode apply_async(), qui peut être considérée comme un complément à delay() et établirons des directives claires sur la relation entre les deux méthodes et quand utiliser l'une ou l'autre. Restez à l'écoute !




Aucun commentaire.