
情境概述

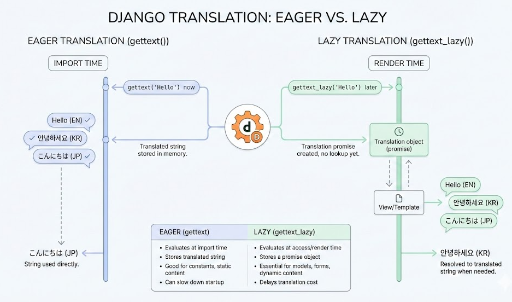
在進行 Django 開發時,我們經常使用 gettext_lazy 來支援多語言。
然而,我們平時使用的 gettext_lazy 在某些時候製作 JSON 响應時可能會出現錯誤。
在這篇文章中,我將詳細解釋為什麼 gettext_lazy 會在 JSON 序列化中引發問題 以及 如何解決這個問題。
正常運作 vs 錯誤發生:情境比較
| 案例 | 正常運作的情況 | 發生錯誤的情況 |
|---|---|---|
LANGUAGE_MAP.get(...) 回傳值位置 |
字典的 value | 字典的 key |
| 序列化可行性 | 可以 (沒有問題) | 無法 (__proxy__ 鍵無法 JSON 轉換) |
問題的核心:為什麼會產生這種差異?
gettext_lazy 回傳的物件是 __proxy__ 類型。這個物件看起來像字串,但實際上不是真實的字串。
Django 的 JsonResponse 或 Python 的 json.dumps() 遵循以下規則:
# ✅ 可行:可以使用 lazy 物件作為 value(自動 str 轉換)
json.dumps({'language': _('English')})
# ❌ 失敗:無法將 lazy 物件作為 key
json.dumps({_('English'): 'language'})
換句話說,要作為字典的 key,必須是真實的字串。
__proxy__ 物件在作為 key 使用時不會自動轉換,因此會導致錯誤。
為什麼作為 value 沒問題,而作為 key 則會出現問題?
gettext_lazy 物件在作為字典的value時不會出現問題。因為 Django 或 Python 在 JSON 序列化過程中會自動將 value 轉換為字串。
但當作為key使用時,JSON 標準強制要求 key 必須是字串。因此 gettext_lazy 物件不會自動轉換,從而導致序列化錯誤。
結論:
- 作為 value 時,會自動進行 str 轉換且不會有問題。
- 作為 key 時,因未自動轉換而導致錯誤。
解決方案
方法 1: 轉換為 gettext(不使用 Lazy)
這是最確定的解決方案。不使用 lazy,直接使用轉換後的字串值。
from django.utils.translation import gettext as _ # 不是 lazy!
LANGUAGE_MAP = {
"en": _("English"),
"ko": _("Korean"),
"ja": _("Japanese"),
}
- 優點:不需要額外處理
- 缺點:翻譯在首次導入時決定,因此可能與某些動態翻譯需求不符
方法 2: 在 JSON 序列化之前強制使用 str() 轉換
如果希望繼續使用 lazy 物件,則在放入 JSON 之前,將 key 轉換為 str()。
lang = str(LANGUAGE_MAP.get(lang_code, lang_code.upper()))
- 優點:幾乎不需要更改現有代碼
- 缺點:每次都需要注意 str 轉換
番外:在客戶端處理翻譯
還可以選擇完全不在伺服器上进行多語言翻譯,而在前端處理。
- 伺服器僅發送語言代碼
- 客戶端 JavaScript 管理翻譯表
這種方法可根據項目選擇使用。
總結
- 切勿將
gettext_lazy用作字典的 key - 在 JSON 序列化之前必須將其轉換為字串
- 最安全的方法是立即使用
gettext轉換為字串 - 如果需要保持現有代碼,請不要忘記使用
str(...)
Jesse 的評論
這個問題是一個常見的錯誤,發生在 Django 的多語言處理與 JSON 响應處理的微妙邊界。
往後記住,不要再問“以前可以,為什麼現在不行?”而是要反思“以前只是運氣好”,好好檢查自己的代碼。
開發者技術的提升,正是因為理解了這種“微妙性”。掌握這一原則後,無論是在 Django 的多語言處理還是在 JSON 响應方面,都能變得更加穩健!



目前沒有評論。