86/100
아래는 러시아어 번역 품질 기준(의미 정확성/기술 용어/자연스러움/번역투 여부)으로 본 평가입니다.
전체 재작성본(러시아어)
Как разработчик видит файл изображения: общая «структура файла» при разных форматах
С точки зрения пользователя файл изображения — это просто «картинка». Для разработчика это другое: бинарные данные, содержащие изображение, и одновременно структурированный файл, в котором описано, как эти данные интерпретировать.
В этой статье мы оставим в стороне особенности конкретных форматов (JPG/PNG/WebP) и сосредоточимся на общей структуре, которая встречается в большинстве файлов изображений. Терминов будет минимум, а объяснение — только через структуру.
Файл изображения — это не «пиксели», а «набор байтов с правилами»
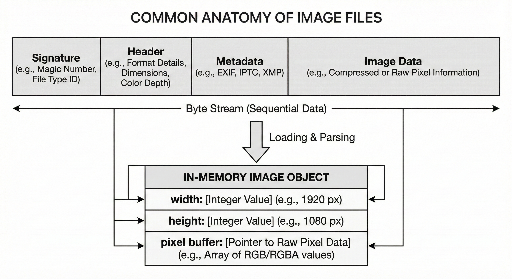
Обычно файл изображения включает три части:
- Идентификация — сообщает, к какому формату относится файл.
- Данные для интерпретации — размер, цветовая модель и другие подсказки для декодирования.
- Собственно данные изображения — как правило, в сжатом или закодированном виде.
Названия и порядок могут отличаться, но общий «скелет» почти всегда одинаков.
1) Сигнатура файла: первый признак типа
Большинство файлов изображений начинается с уникального набора байтов — сигнатуры. Это надежнее, чем расширение.
- Расширение можно поменять как угодно.
- Сигнатуру сложно «подделать», если файл не соответствует формату.
Поэтому тип файла определяют по первым байтам, а не по имени.
Сигнатура обычно занимает всего несколько байтов, но именно с нее начинается решение: стоит ли читать заголовок и как именно.
2) Заголовок: минимум данных для восстановления пикселей
После сигнатуры идет заголовок. В нем — сведения, которые нужны декодеру, чтобы восстановить пиксельный массив.
Обычно это:
- Ширина/высота
- Цветовая модель (например, RGB и наличие альфа-канала)
- Глубина цвета (8 бит, 16 бит и т. д.)
- Способ сжатия/кодирования и дополнительные этапы обработки
Главная мысль: данные изображения редко «читаются напрямую». Заголовок задает правила, по которым их нужно интерпретировать. Без корректного заголовка даже сохраненные данные могут оказаться бесполезными.
3) Метаданные: информация об изображении, а не сами пиксели
Помимо самой картинки файл может хранить дополнительные данные. Они не всегда нужны для отображения, но часто важны — или проблемны.
Примеры:
- Время съемки, параметры камеры, ориентация
- Сведения о цветовом пространстве
- Встроенная миниатюра (thumbnail)
- Автор, права, информация о программе
С точки зрения разработки метаданные:
- Опциональны
- Иногда влияют на поведение (например, ориентация)
- Могут создавать риски приватности (например, геоданные)
Поэтому в некоторых системах нужно обрабатывать не только пиксели, но и метаданные.
4) Данные изображения: обычно в сжатом/закодированном виде
Файл изображения предназначен для хранения и передачи, поэтому «сырые» пиксели обычно не сохраняют как есть.
Типичные варианты:
- Без сжатия (редко или ограниченно) — значения пикселей напрямую
- Сжатие/кодирование (чаще всего) — преобразование ради меньшего размера
Ключевой вывод:
Содержимое файла редко является готовым массивом пикселей. Чтобы получить пиксели в памяти, нужна декодировка.
Файл оптимизирован под хранение, а пиксельный буфер в памяти — под обработку.
5) «Файл» и «память»: два представления одного изображения
Одно и то же изображение существует в двух формах:
- На диске — поток байтов: сигнатура + заголовок/метаданные + данные
- В памяти — объект с шириной/высотой, буфером пикселей и, возможно, дополнительной информацией
Типичный процесс:
- Прочитать начало файла и определить формат (сигнатура).
- Прочитать заголовок и понять, как декодировать.
- Декодировать данные в пиксельный буфер.
- Затем выполнять ресайз, кроп, фильтры и т. п.
Так что файл изображения — это не просто «картинка», а структурированный набор данных.
Итог: читать файл изображения — значит интерпретировать его структуру
Детали зависят от формата, но общая последовательность почти всегда одна: сигнатура → заголовок → (опционально) метаданные → данные изображения. Это не случайность, а дизайн, который делает интерпретацию безопасной и последовательной.
Когда мы говорим «открыть изображение», мы на деле:
- Определяем формат по сигнатуре
- Получаем правила интерпретации из заголовка
- При необходимости учитываем метаданные
- Восстанавливаем пиксели в памяти через декодирование
Понимание этой структуры помогает быстрее диагностировать проблемы даже без готовых библиотек.
Анонс следующей статьи
- Как связаны
python-magicи команда Linuxfileи как они определяют тип файла. - Чем отличаются
open(),load()иverify()в Pillow (PIL) и когда что применять.
Смотрите также: