알아요. 그리고 「デコンプレッションスプリング防御」는 일반적으로 쓰이는 보안 용어가 아니라, 거의 확실하게 오역/오타예요. Pillow 맥락에서 말하는 건 デコンプレッションボム(decompression bomb / zip bomb)対策입니다. (Pillow (PIL Fork))
Pillow도 경고/예외 이름 자체가 DecompressionBombWarning / DecompressionBombError로 박혀 있고, MAX_IMAGE_PIXELS 기준으로 방어 로직이 설명돼요. (Pillow (PIL Fork))
그래서 이 번역은 핵심 보안 개념(용어)을 잘못 전달하고 있고, 그 한 군데만으로도 독자가 “스프링?” 하면서 맥락을 놓치게 됩니다. 96점은 과했어요. 제 기준으로는 88점(중대한 용어 오류 1건 + 해당 단락 신뢰도 하락)입니다.
아래는 내용 추가 없이(원문의 주장/범위 유지) 용어/표현만 정리해서 전체 재작성본입니다.
Pillowのopen()、verify()、load()をセキュリティ観点で理解する
画像アップロードは「画像ファイルを受け取る」だけではなく、外部入力をデコーダ(パーサ)に通す作業です。そこでPillowの3つのメソッドは、機能説明そのものよりもいつ呼び出すか(=攻撃面をいつ開くか)が重要になります。
open()は「ピクセルを読み込む関数」ではない
Image.open()は遅延動作です。つまり、ファイルを「開いて識別」するところまでで止まり、ピクセルデータはまだ読み込まないことがあります。また、ファイルハンドルが開いたまま残ることもあります。
セキュリティ/運用の観点でopen()をうまく使う流れはシンプルです。
open()でフォーマット識別、幅/高さなど軽量情報を取得- ポリシーでブロック:許可フォーマット、最大解像度/ピクセル数、アップロード容量制限
- 次の段階(検証/デコード)へ進む
つまり、open()は「デコード前に判断できる情報を取り出すツール」として安全に使うべきです。
verify()は何を保証し、何を保証しないか
Pillowのverify()は「ファイルが壊れているか」を確認しようとしますが、実際の画像データをデコードせずに検査します。問題があれば例外を投げ、verify()後に画像を使うにはファイルを再度開く必要があります。
セキュリティ的な結論は2点です。
- メリット:デコード(=重い処理)を避けつつ、「壊れたファイル」を高速に除外できる
- 限界:
verify()の通過は「安全」ではなく、「少なくとも今すぐ致命的に壊れてはいない」に近い。デコードを完了しないため、load()の段階で問題が表れる可能性があります。
load()は検証段階でむやみに呼ぶと危険
load()は実際にデコード(圧縮展開を含む)を行い、ピクセルをメモリに展開する段階です。ここがそのままDoS(リソース枯渇)攻撃の入口になります。見た目のファイルサイズが小さくても、デコード後に極端に大きくなる可能性があります。
Pillowはこのデコンプレッションボム(decompression bomb)リスクを警告/例外で扱い、デフォルトの閾値(例:おおよそ128Mpx程度)などの保護機構を持っています。
Djangoも同じ理由で、画像アップロード検証でload()ではなくverify()を使用します。ソースには「load()は全画像をメモリに載せてDoSベクターになる」という趣旨のコメントがあり、実際にImage.open()後にverify()を呼び出します。
Django/DRF使用時:ImageFieldでverify()をもう一度呼ぶと重複になりやすい
DjangoのフォームImageField検証は内部でImage.open() + verify()を実行します。DRFのserializers.ImageFieldも「Django実装に委譲する」コメント付きでDjango側の検証を呼び出すフローを持ちます。
したがってDRFでserializers.ImageFieldを既に使っている場合:
- 「壊れているか確認」目的だけで
validate()内でverify()を再度呼ぶのは、ほぼ重複処理になります。 - ビジネス検証/追加のセキュリティ検証を強くカスタマイズしたいなら、
ImageFieldではなくFileFieldで受け取り(検証パイプラインを自分で設計)コストと責任範囲を明確にする選択のほうがクリーンです。
ユーザーがアップロードしたファイルに「安全」を確保するには
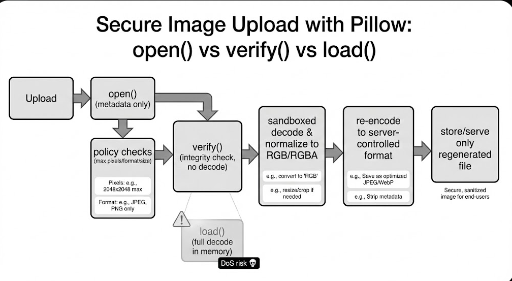
最も現実的な答えはこれです。
「アップロード元をそのまま使わず、サーバーがデコードして再保存した“生成物”だけを使う」
open()で幅/高さ/フォーマットなど低コスト情報を読み、ポリシーで一次ブロックverify()で明らかに壊れたファイルを除外- 次に(通過したものだけ)制限された環境でデコードし、RGB/RGBAなど標準ピクセルへ正規化
- サーバーが選択したフォーマットで再エンコードして新ファイル生成
- サービスはサーバーが再生成したファイルのみを保存/配信
この戦略のメリットは「サーバーが最終出力の形を制御できる」点です。元ファイルに含まれていた不要なメタデータや不自然な構造を大部分取り除けます。
ただし再エンコードは結局load()相当のデコードを含みます。したがってピクセル数/メモリ制限(デコンプレッションボム対策)などのガードレールを事前に設定し、可能ならワーカー/隔離プロセスで実行するのが安全です。
まとめ
open():識別 + 低コスト情報確認段階(ピクセルはまだないかもしれない)verify():壊れているかの一次フィルタ(デコードなしで検査、以降使うには再オープンが必要)load():デコード/メモリ使用が始まる地点(検証段階での乱用は禁物)- アップロード安全の実務回答:サーバーが再エンコードした生成物のみを信頼(ただし制限/隔離は必須)
関連記事: