Django/Security Bild-Upload, wenn man einfach alles annimmt, kann der Server abstürzen: Ein umfassender Leitfaden für Sicherheit und Effizienz
In Web‑Services ist das Hochladen von Bildern ein „immer vorhandenes“ Feature, das leicht umgesetzt werden kann. Doch der Upload‑Endpunkt ist der direkteste Pfad, über den externe Daten in den Server gelangen, und für Angreifer ist es der günstigste Weg, maximalen Schaden zu verursachen (z. B. Web‑Shell‑Upload, Bild‑Parser‑Schwachstellen, DoS usw.).
Dieser Beitrag fasst zusammen, wie man das scheinbar widersprüchliche Ziel „Sicherheit paranoid, Ressourcen sparsam“ beide erfüllt. Das Kernprinzip ist einfach:
- Im Validierungs‑Schritt möglichst wenig lesen (keine Dekodierung, nur Header/Metadaten)
- Im Speicherschritt alles neu erzeugen (Transcoding zur Sanitization)
Die Essenz der Upload‑Sicherheit: „Vertraue nicht, bis du es wirklich brauchst“

Im Upload können wir kaum etwas vertrauen.
- Dateiname: kann vom Nutzer geändert werden
- Erweiterung: kann beliebig geändert werden
- Content‑Type: wird vom Client angegeben
- Dateiinhalte: werden vom Angreifer erstellt
Daher reduziert sich die Strategie auf zwei Punkte.
- Schnelle, kostengünstige Filter (cheap checks)
- Der endgültige Speicher ist immer vom Server erzeugt (server‑generated artifact)
Häufiges Missverständnis: „Um sicher zu sein, muss man alles lesen?“
Sichere Entwickler machen oft den Fehler, im Validierungs‑Schritt folgenden Code einzufügen.
img = Image.open(file)
img.verify() # oder img.load()
Das Problem ist, dass dies Server‑Ressourcen dem Angreifer im Voraus zur Verfügung stellt.
Warum ist das gefährlich?
- Decompression Bomb
Eine Datei, die nur wenige MB groß erscheint, kann beim Dekodieren mehrere GB werden.
load()führt die eigentliche Pixel‑Dekodierung aus und kann Speicher/CPU sofort erschöpfen, was zu DoS führt. - Unnötiger I/O
verify()liest die Datei bis zum Ende, was hohe I/O‑Kosten verursacht. Für weitere Verarbeitung muss man häufigseek(0)oder die Datei erneut öffnen.
Fazit: Im Validierungs‑Schritt sollten keine Pixel dekodiert werden. Header + Metadaten + Auflösung‑Grenze reichen für die erste Verteidigung.
Verteidigung ist kein Ein‑Schritt‑Weg, sondern 3‑Stufen: Defense in Depth
Bild‑Upload kann nicht mit einer einzigen if‑Anweisung beendet werden. Für ein realistisches Gleichgewicht muss man Schichten aufbauen.
1. Stufe: Erweiterungen sind Lügen – MIME‑Erkennung über Magic Number
profile.png sagt nichts aus. Man muss die Signatur (Magic Number) lesen, um den tatsächlichen Typ zu prüfen.
- Lese nicht die ganze Datei. Die ersten 1–2 KB reichen.
- Beispiel‑Bibliothek:
python‑magic(libmagic‑basiert)
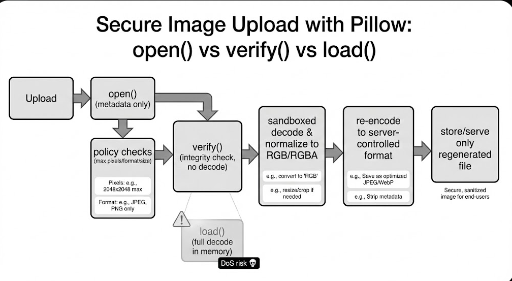
2. Stufe: Pillow ist „nur öffnen“ noch sicher – Lazy Loading zur Auflösungsbegrenzung
Image.open() von Pillow lädt normalerweise keine Pixel sofort, sondern nur den Header. Man kann diese Eigenschaft nutzen, um vor einer Dekodierungs‑/Speicher‑Explosion die Auflösung zu prüfen.
- Prüfen:
width * height <= MAX_PIXELS - Tipp: Nutze
sizeohneload()/verify()
3. Stufe: Die beste Sanitization ist „neu zeichnen“ – Transcoding
Das wichtigste Prinzip.
Speichere das Original nicht.
Bilder können Metadaten (EXIF), Profile, Slack‑Platz, Parser‑Tricks usw. in nicht‑Pixel‑Bereichen verstecken. Wenn man nur die Pixel extrahiert und vom Server in ein neues Format speichert, werden viele dieser Gefahren automatisch entfernt.
- Empfohlen: WebP (oder AVIF/JPEG) – der Server re‑kodiert und speichert
- Effekt: Sanitizing + Größenoptimierung + konsistente Format‑Politik
Praxis‑Implementierung: DRF Serializer (Sicherheit + Speicher‑Effizienz)
Der folgende Code verkörpert die Philosophie „im Validierungs‑Schritt möglichst wenig lesen, im Speicherschritt neu erzeugen“.
f.sizeist bereits von Django als Metadaten bekannt und kann genutzt werden- Magic Number liest nur den Anfang
- Pillow prüft nur die Auflösung
- Endgültiger Speicher erfolgt via Transcoding (WebP)
- Nach jedem Schritt
seek(0)um den Dateizeiger zurückzusetzen
from io import BytesIO
import magic
from PIL import Image, ImageOps, UnidentifiedImageError
from rest_framework import serializers
# Richtlinien (an die Service‑Anforderungen anpassen)
MAX_SIZE = 5 * 1024 * 1024 # 5 MB
MAX_PIXELS = 4_194_304 # 2048 * 2048 ≈ 4 MP
ALLOWED_MIME = {"image/png", "image/jpeg", "image/webp"}
class SecureImageUploadSerializer(serializers.Serializer):
file = serializers.ImageField()
def validate_file(self, f):
# [1] Größenbeschränkung: billigster Filter
if f.size > MAX_SIZE:
raise serializers.ValidationError("Datei ist zu groß.")
# [2] MIME‑Erkennung über Magic Number: Erweiterung/Content‑Type nicht vertrauen
f.seek(0)
head = f.read(2048) # nur Anfang
f.seek(0)
mime = magic.from_buffer(head, mime=True)
if mime not in ALLOWED_MIME:
raise serializers.ValidationError("Nicht unterstütztes Dateiformat.")
# [3] Auflösungsbeschränkung: ohne load/verify nur Header‑basierte Größe prüfen
try:
with Image.open(f) as img:
w, h = img.size
if (w * h) > MAX_PIXELS:
raise serializers.ValidationError("Bildauflösung ist zu hoch.")
except UnidentifiedImageError:
raise serializers.ValidationError("Ungültiges Bild.")
except Exception:
raise serializers.ValidationError("Fehler bei der Bildvalidierung.")
finally:
f.seek(0)
return f
def create(self, validated_data):
f = validated_data["file"]
# Endgültiger Speicher: immer vom Server erzeugt (Sanitizing)
try:
with Image.open(f) as img:
# EXIF‑Rotation korrigieren (besonders bei mobilen Uploads)
img = ImageOps.exif_transpose(img)
# Sicheres und konsistentes Farbraum‑Normalisieren
if img.mode not in ("RGB", "RGBA"):
img = img.convert("RGB")
out = BytesIO()
img.save(out, format="WEBP", quality=85, method=6)
out.seek(0)
safe_bytes = out.getvalue()
# Hier safe_bytes in den Speicher laden.
# - Dateinamen zufällig generieren (UUID)
# - Verzeichnis‑Sharding (z. B. ab/cd/uuid.webp)
# - In der DB nur der vom Server erzeugte Schlüssel speichern
return safe_bytes
except Exception:
raise serializers.ValidationError("Fehler bei der Bildverarbeitung.")
„Paranoide Sicherheit“ vs. „Ressourceneffizienz“ ausbalancieren
Der entscheidende Ausgleich liegt hier.
Im Validierungs‑Schritt nicht gierig sein
Der Validierungs‑Schritt ist der Bereich mit dem höchsten Traffic und dem niedrigsten Kosten‑Barrier. Wenn man dort load() oder ähnliche „teure“ Operationen ausführt, kann der Angreifer die Serverkosten beliebig erhöhen.
- ✅ Größen‑Limit / Header‑basierte MIME / Auflösungs‑Limit
- ❌ Pixel‑Dekodierung erzwingen / komplette Datei lesen / mehrfach öffnen
„Wirklich sicher“ entsteht im Speicherschritt
Der Validierungs‑Schritt filtert, der Speicherschritt standardisiert. Wenn der Server neue Byte‑Streams erzeugt, wird die Sicherheit und Wartbarkeit deutlich verbessert.
- Format‑Einheit → vereinfachte Cache‑Strategie / Thumbnail‑Pipeline
- Metadaten‑Bereinigung → Entfernung von sensiblen Daten (z. B. EXIF GPS)
- Reduzierung von Angriffsmöglichkeiten durch bösartige Payloads
Wenn man diese Punkte beachtet, wird es noch sicherer!
- Dateinamen niemals vertrauen – vom Server generieren (UUID empfohlen)
- Uploads nicht direkt an App‑Server (bei großen Systemen: presigned URL für Objekt‑Storage + asynchrone Prüfung/Umwandlung)
- Verarbeitungszeit begrenzen / Worker‑Isolation Bild‑Umwandlung beansprucht CPU. Halte die Web‑Request‑Antwortzeit kurz, delegiere an Worker/Queue.
- Logs/Metrics Ablehnungsgründe (MIME‑Mismatch, Auflösungs‑Überschreitung, Größen‑Überschreitung) sammeln, um Angriffs‑/Missbrauchsmuster frühzeitig zu erkennen.
Checkliste zum Zusammenfassen
- Lade die komplette Datei nicht in den Speicher.
read()nur für den Anfang, der Rest streamen. - Vertraue Erweiterung/Content‑Type nicht – prüfe MIME über Magic Number.
- Im Validierungs‑Schritt keine
load()/verify()– prüfe nur die Auflösung. - Speichere das Original nicht – erstelle mit Transcoding einen neuen Server‑Datei.
- Setze den Dateizeiger nach jedem Schritt zurück (
seek(0)).
Upload‑Sicherheit beginnt mit dem Misstrauen gegenüber dem Nutzer, aber die Performance hängt davon ab, wie gut man die System‑Funktionsweise versteht. Beide Aspekte zu berücksichtigen, verhindert, dass der Service ausfällt.
Weitere verwandte Beiträge

Es sind keine Kommentare vorhanden.