python-magic:最实用的文件内容识别方法,取代扩展名
当服务器具备图片上传功能时,往往会遇到以下需求。
- “
.png上传了…真的 PNG 吗?” - “先判断文件是图片还是文档再分流。”
- “在使用外部解析器(Pillow/OpenCV)之前,至少先确认类型。”
此时最稳妥的起点不是扩展名,而是文件内容。而实现“基于内容识别”最简便的工具就是 python-magic。
python-magic 是什么?

python-magic 是一个 Python 包,它封装了 C 语言库 libmagic。libmagic 通过检查文件的头部(前几字节)等特征来识别文件类型。类似的功能在 Unix 的 file 命令中也能找到。
简而言之:
file(Linux 命令)= “终端使用的接口”libmagic= “核心引擎(识别逻辑)”python-magic= “Python 调用 libmagic 的薄封装”
本文将围绕 python-magic,结构化地说明“这个引擎究竟是如何识别文件类型的”。
核心引擎(libmagic)是如何工作的?
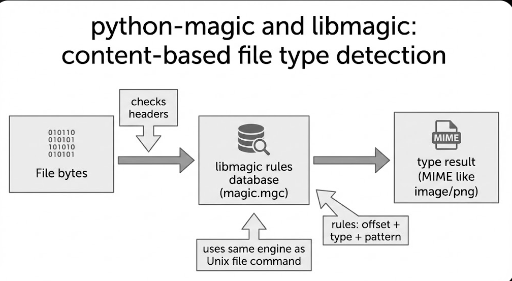
libmagic 的本质很简单:
“读取包含文件类型识别规则的数据库,按规则检查文件字节,给出最合理的结论。”
这里的数据库即为 magic database(magic 数据库),供 file/libmagic 一起使用。通常以编译后的形式(magic.mgc)安装在系统中。
1) “魔法文件”是规则集合
这些规则基本由以下几部分组成:
- 查看位置(offset:文件的哪一字节)
- 读取方式(type:字节/字符串/整数等)
- 比较值(expected value/pattern)
- 输出结果(message/MIME 等)
file 的手册也说明它在检查 magic patterns。规则逐行测试(offset/type/value/message),若匹配则进入更具体的子测试,形成层级结构。
想了解 Linux file 命令的细节,请点击以下链接。
2) 规则数据库有“文本原始”和“编译结果”两种形式
魔法数据库最初是人可读的文本片段集合,为了性能,通常也提供编译后的二进制数据库(.mgc)。
3) 最终目标是“看文件内容而非扩展名”
file 之所以被视为“内容型类型推断器”已有悠久历史。python-magic 就是把这一哲学用“一行 Python 代码”实现的工具。
如何使用 python-magic?
常见的使用模式有两种。
1) 以 MIME 类型获取(最实用)
适用于上传处理、路由、日志/指标等。
import magic
mime = magic.from_file("upload.bin", mime=True)
print(mime) # 例如: image/png
python-magic 基于 libmagic 提供文件类型识别功能,官方说明与 file 命令同属一类。
2) 直接以 bytes 进行识别(上传流更友好)
在将文件写入磁盘之前,想先快速查看上传的字节片段时非常有用。
import magic
with open("upload.bin", "rb") as f:
head = f.read(4096)
mime = magic.from_buffer(head, mime=True)
print(mime)
(基于缓冲区的识别是“文件保存前的第一道过滤器”)
开发者视角:在哪些场景下有用?
1) 上传验证的第一道防线
- 不仅凭扩展名做分流
- 至少确认“是否可以作为图片处理”
2) 处理管道的分流点
- 若是图片,则进入缩放/缩略图管道
- 若是 PDF/ZIP,则交给其他工作者
- 若是未知类型,则隔离/拒绝/进一步验证
3) 在调用“重量级解码器”之前降低成本
Pillow 等解码器功能强大,但调用本身会增加内存/CPU/攻击面。python-magic 可以在此之前判断“是否值得继续处理”。
重要的现实检查:libmagic 仅是 推断/识别 工具。若目标是安全完整的判定(拦截恶意负载等),仍需额外验证(白名单、大小限制、沙箱解码等)。
结语:python-magic 是“把文件类型识别带到代码中的最轻量方式”
python-magic 并不提供图片处理本身,而是快速告诉你“该文件应被视为哪种类型”。
- 引擎:
file同类的 libmagic - 识别方式:规则数据库 + 字节检查
- 开发实战:上传验证、路由、成本节约尤为适用
掌握它后,即使在库不足的环境中,也能构建“识别 → 分流 → 安全防护”的完整流程。
下期预告
- Pillow(PIL)的
open()、load()、verify()各自保证什么,何时使用,如何工作,做一份整理。
相关阅读
目前没有评论。