开发者视角下的图像文件:格式虽异却共享的“文件结构”骨架
从用户的角度看,图像文件就是“一幅画”。 从开发者的角度看,图像文件既是“存放图像的二进制数据”,又是“包含如何解析这些二进制数据的结构化文档”。
本文暂时不讨论 JPG/PNG/WebP 等各自的特点,而只整理图像格式无论如何都共通出现的结构。术语尽量简化,只按结构说明。
图像文件不是“像素块”,而是“包含规则的字节集合”

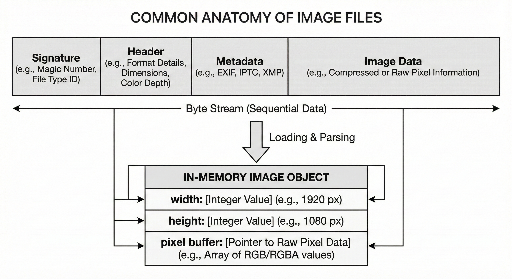
图像文件的核心通常有三部分。
- 识别区域:告诉文件是什么格式
- 解析所需信息:尺寸、色彩表示等“如何读取”
- 实际图像数据:通常以压缩/编码形式存储
不同格式的名称和布局不同,但大体骨架基本不变。
1) 文件签名:最先告诉你“这是什么文件”
大多数图像文件在文件最前面放置唯一的字节模式。 这比扩展名更可靠。
- 扩展名可以随意改。
- 而文件前的签名如果不符合对应格式,几乎无法识别。
因此开发者判断文件类型时,
- 不是看“文件名(.png/.jpg)”,
- 而是看“文件内容的前几个字节”。
签名通常很短(几字节),但它是决定是否读取后续头部的起点。
2) 头部:构建像素所必需的最小信息
签名确认格式后,接下来通常是头部。 头部包含解码器(图像加载器)恢复像素所必需的信息。
典型信息包括:
- 宽/高:width, height
- 色彩表示方式:如 RGB、是否有透明度(Alpha)
- 精度(比特数):8 位、16 位等
- 读取方式:是否压缩/编码,所需处理
关键点是:
像素数据往往“本身难以直接读取”, 文件先在头部写入“读取方法”。
没有或损坏的头部,即使有像素数据,也难以正常解析。
3) 元数据:图像本身之外的“关于图像的信息”
图像文件除了可见图像外,还可携带附加信息。 这些信息不一定对恢复像素必需,但在产品中常常成为问题或有用。
- 拍摄时间、相机信息、方向(旋转)
- 色彩空间信息
- 预览用小图(缩略图)
- 其他制作工具、版权标识等
从开发角度看,元数据的要点很简单。
- 可能有也可能没有。
- 可能影响正常运行(如方向信息)。
- 可能涉及安全/隐私(如位置信息)。
因此“只取像素”并不总是足够,某些系统需要同时处理元数据。
4) 图像数据:大多数以“压缩/编码状态”存储
图像文件的目的在于存储和传输。 因此实际图像数据通常是以下两种之一。
- 无压缩(少见或有限):直接存储像素值
- 压缩/编码(大多数):为减小尺寸而转换的形式
开发者需要记住的核心是:
文件内的图像数据很可能不是“直接的像素数组”。 通常需要解码后才能在内存中得到像素。
也就是说,文件是为存储优化的,而内存中的像素缓冲区是为处理优化的。 两者形态必然不同。
5) “文件”与“内存”呈现不同
同一幅图像在开发者眼中有两种表现。
- 磁盘上的图像文件是流:签名 + 头部/元数据 + 数据按顺序排列的字节流。
- 内存中的图像是对象:拥有 width/height、像素缓冲区(以及辅助信息)的结构化对象,便于开发者访问。
处理流程通常如下。
- 读取文件前部推断格式(签名)
- 读取头部决定“如何解码”
- 解码数据到内存中的像素形式
- 之后才进行缩放/裁剪/滤镜等处理
从这个视角看,“图像文件”不仅是简单的画,而是可解析结构的数据。
结语:读取图像文件即是解析结构
图像文件的细节实现因格式而异,但从开发者角度看,通用流程是 签名 → 头部 →(可选)元数据 → 图像数据。 这一顺序不是随意的,而是“安全、统一解析文件”的设计。
我们常说的“打开图像(open)”实际上包含:
- 读取文件前部识别格式
- 通过头部获取解析规则
- 如有必要,考虑元数据
- 最终将图像数据恢复为内存中的像素
也就是说,图像不仅是像素,更是携带结构与规则的文件。了解这一点后,即使没有库,也能更快诊断问题,区分在哪一步(识别/头部/解码)出错。
下期预告
- 讨论
python-magic与 Linux 的file命令的关系,以及它们如何实现“文件类型判别”。 - 说明 Pillow(PIL)中
open()、load()、verify()等核心方法的实际差异,以及在何种场景下选择哪种方法。
相关阅读:
目前没有评论。