
情况概述

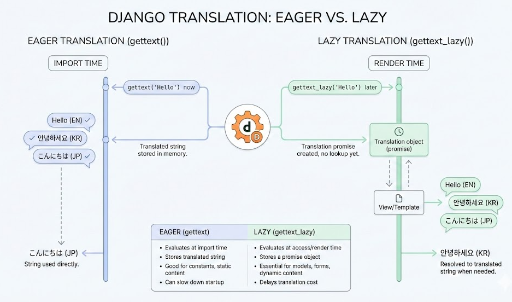
在进行Django开发时,经常会使用gettext_lazy来实现多语言支持。
然而,有时在生成JSON响应时,gettext_lazy会突然产生错误。
本文将详细解释为什么gettext_lazy在JSON序列化中会引发问题以及如何解决它。
正常工作 vs 发生错误:情境比较
| 案例 | 正常工作的情况 | 发生错误的情况 |
|---|---|---|
LANGUAGE_MAP.get(...) 返回值位置 |
字典的值 | 字典的键 |
| 是否可序列化 | 可行(没有问题) | 不可行(__proxy__键无法进行JSON转换) |
问题的核心:为什么会有这样的差异?
gettext_lazy返回的对象是__proxy__类型。这个对象看起来像字符串,但实际上并不是一个真正的字符串。
Django的JsonResponse或Python的json.dumps()遵循以下规则:
# ✅ 可行:值可以是lazy对象(自动转换为str)
json.dumps({'language': _('English')})
# ❌ 失败:键不能是lazy对象
json.dumps({_('English'): 'language'})
也就是说,字典的键必须是一个真正的字符串。
__proxy__对象在作为键时不会自动转换,因此会引发错误。
为什么作为值没有问题,而作为键会出现问题?
gettext_lazy对象在作为字典的值时并没有问题。因为Django或Python会在JSON序列化过程中将值自动转换为字符串。
但是作为键时,JSON标准要求键必须是字符串。在这种情况下,gettext_lazy对象不会自动转换,从而导致序列化错误。
结论:
- 作为值使用时,会自动进行str转换,没有问题。
- 作为键使用时,不会自动进行转换,因此会发生错误。
解决方案
方法 1: 转换为gettext(不使用Lazy)
这是最可靠的方法。直接使用转换为字符串的值,而不使用lazy。
from django.utils.translation import gettext as _ # 不是lazy!
LANGUAGE_MAP = {
"en": _("English"),
"ko": _("Korean"),
"ja": _("Japanese"),
}
- 优点:不需要额外处理
- 缺点:在首次导入时翻译决定,因此可能与某些动态翻译需求不同
方法 2: 在JSON序列化前强制应用str()
如果想继续使用lazy对象,则在将其放入JSON之前,将键转换为str()。
lang = str(LANGUAGE_MAP.get(lang_code, lang_code.upper()))
- 优点:几乎不需要改变现有代码
- 缺点:必须时刻关注str转换
附录: 在客户端处理翻译
也可以完全不在服务器上进行多语言翻译,而是在前端处理。
- 服务器只发送语言代码
- 客户端JavaScript管理翻译表。
这个方法可以根据项目进行选择。
总结
- 绝对不要将
gettext_lazy用作字典键 - 在JSON序列化之前必须转换为字符串
- 最安全的方法是使用
gettext立即转换为字符串 - 如果需要保持现有代码,请记得使用
str(...)
Jesse的评论
这个问题通常发生在Django处理多语言和JSON响应处理之间非常微妙的界限上。
请记住,不要再想“以前能行,为什么现在不行?”而是要想“以前只是运气好”,从而检查代码。
开发者的能力在于理解这种“微妙性”的时刻。掌握这个原理,可以使Django的多语言处理和JSON响应都更加坚固!



目前没有评论。