Hoe ontwikkelaars een afbeeldingsbestand zien: de gemeenschappelijke "bestandsstructuur" ondanks verschillende formaten
Vanuit het oog van een gebruiker is een afbeeldingsbestand simpelweg "een afbeelding". Vanuit het oog van een ontwikkelaar is het echter een ander verhaal. Een afbeeldingsbestand is binair data die een afbeelding bevat én tegelijkertijd een gestructureerd document dat beschrijft hoe die data geïnterpreteerd moet worden.
In dit artikel leggen we de gemeenschappelijke structuur uit die in alle afbeeldingsformaten voorkomt, zonder ons te verdiepen in de specifieke kenmerken van JPG/PNG/WebP. We beperken ons tot de basisstructuur en minimaliseren de terminologie.
Een afbeeldingsbestand is geen "pixelblok", maar een "byte‑bundel met regels"
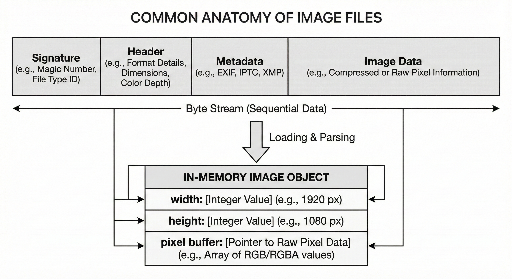
De kern van een afbeeldingsbestand bestaat meestal uit drie onderdelen:
- Identificatiegebied: geeft aan om welk type bestand het gaat
- Informatie voor interpretatie: bevat zaken als afmetingen, kleurrepresentatie, enz.
- Echte afbeeldingsdata: meestal gecomprimeerd of gecodeerd
Hoewel de namen en volgorde per formaat kunnen verschillen, volgt de algemene structuur vrijwel altijd dit patroon.
1) Bestandshandtekening: het eerste stukje dat zegt "dit is een afbeelding"
De meeste afbeeldingsbestanden beginnen met een uniek byte‑patroon, de handtekening. Dit is betrouwbaarder dan de bestandsextensie.
- De extensie kan door de gebruiker worden gewijzigd.
- De handtekening is moeilijk te misleiden; een bestand dat niet aan de handtekening voldoet, is waarschijnlijk geen afbeelding.
Voor ontwikkelaars is het bepalen van het bestandstype dus gebaseerd op de eerste bytes, niet op de bestandsnaam.
De handtekening is meestal kort, maar vormt het startpunt voor het lezen van de header.
2) Header: de minimale informatie die nodig is om pixels te reconstrueren
Na de handtekening volgt de header. Deze bevat alle informatie die een decoder nodig heeft om de pixels te herstellen.
Typische gegevens:
- Breedte / hoogte: width, height
- Kleurrepresentatie: RGB, RGBA, etc.
- Bits per pixel: 8, 16, etc.
- Compressie / codering: of en hoe de data moet worden verwerkt
Belangrijk: pixeldata is vaak niet direct leesbaar; de header vertelt hoe je die data moet decoderen.
Zonder een intacte header is het moeilijk om de pixeldata correct te interpreteren.
3) Metadata: informatie over de afbeelding, niet de afbeelding zelf
Naast de zichtbare afbeelding kunnen afbeeldingsbestanden extra informatie bevatten die niet noodzakelijk is voor het renderen, maar wel belangrijk kan zijn voor toepassingen.
Voorbeelden:
- Opname‑tijd, camera‑gegevens, rotatie
- Kleur‑ruimte‑informatie
- Voorvertonings‑thumbnail
- Productie‑tools, copyright‑informatie
Voor ontwikkelaars zijn de belangrijkste punten:
- Optioneel – kan aanwezig of afwezig zijn.
- Kan de werking beïnvloeden – bijvoorbeeld rotatie‑informatie.
- Kan privacy‑risico’s met zich meebrengen – zoals locatie‑gegevens.
Daarom moet in sommige systemen ook metadata worden verwerkt.
4) Afbeeldingsdata: meestal gecomprimeerd of gecodeerd
Het doel van een afbeeldingsbestand is opslag en overdracht. De daadwerkelijke data is meestal:
- Ongecomprimeerd (zeldzaam): pixelwaarden worden direct opgeslagen.
- Gecomprimeerd / gecodeerd (meestal): om de bestandsgrootte te verkleinen.
Kernpunt voor ontwikkelaars:
De data in het bestand is vaak niet een directe pixelarray. Een decodering is nodig om de data in geheugen om te zetten.
Het bestand is geoptimaliseerd voor opslag, de pixelbuffer voor verwerking.
5) "Bestand" vs. "geheugen" – twee verschillende weergaven
Zelfs bij dezelfde afbeelding ziet een ontwikkelaar twee vormen:
- Bestand op schijf: een stroom van bytes – handtekening + header/metadata + data.
- Object in geheugen: een gestructureerd object met width/height, pixelbuffer en aanvullende info.
Standaardverwerking:
- Lees de handtekening om het type te bepalen.
- Lees de header om de decodering te bepalen.
- Decodeer de data naar een pixelbuffer.
- Pas daarna bewerkingen toe (resize, crop, filter).
Deze kijk maakt duidelijk dat een "afbeeldingsbestand" meer is dan een simpel plaatje; het is een interpreteerbare structuur.
Afsluiting: "Een afbeelding lezen" betekent een structuur ontleden
Afbeeldingsbestanden verschillen in detail, maar van een ontwikkelaarsperspectief volgen ze altijd het patroon: handtekening → header → (optioneel) metadata → afbeeldingsdata.
Het openen van een afbeelding omvat:
- Identificatie van het type via de handtekening.
- Vaststellen van de interpretatieregels via de header.
- Eventueel rekening houden met metadata.
- Decoderen van de data naar een pixelbuffer in geheugen.
Met deze kennis kun je sneller problemen diagnosticeren, zelfs zonder een library, en precies bepalen op welk niveau iets misgaat.
Vooruitblik op het volgende artikel
- Hoe
python-magicen het Linux‑commandofilesamenwerken om bestandstypen te bepalen. - De verschillen tussen
open(),load()enverify()in Pillow (PIL) en wanneer je welke methode moet gebruiken.
Meer gerelateerde artikelen: