開発者が見る画像ファイル:フォーマットが違っても共通する「ファイル構造」の骨格
画像ファイルをユーザー目線で見ると「一枚の絵」です。開発者目線では別の見方になります。画像ファイルは絵を含むバイナリデータであると同時に、そのバイナリをどう解釈するかまでを含む構造化ドキュメントに近いものです。
この記事では JPG/PNG/WebP など「種類別の特徴」は一旦置き、画像フォーマットに関係なく共通して現れる構造だけを整理します。用語は最小限に抑え、構造を基準にのみ説明します。
画像ファイルは「ピクセルの塊」ではなく「規則を含むバイトの集合」だ

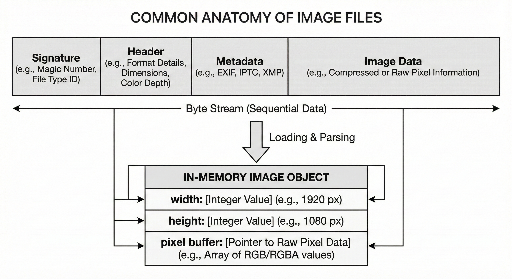
画像ファイルを構成するコアは通常この 3 つです。
- 身元を確認する領域:このファイルがどの形式かを知らせる
- 解釈に必要な情報:サイズ、色表現など「読む方法」を含む
- 実際の画像データ:通常は圧縮/エンコードされた形で保存される
フォーマットごとに名前と配置は異なりますが、大枠はほぼこのパターンから外れません。
1) ファイルシグネチャ:『このファイルは何か』を最初に語る部分
ほとんどの画像ファイルは ファイルの先頭にユニークなバイトパターン を置きます。これは拡張子より信頼できるヒントです。
- 拡張子はユーザーが好きに変えられます。
- それに対し、ファイル先頭のシグネチャは そのフォーマットに従わないと判別が難しい です。
したがって開発者はファイルタイプを判定する際、
- 「ファイル名(.png/.jpg)」ではなく
- 「ファイル内容の最初のバイト」を見て判断します。
このシグネチャは通常「数バイトレベル」で短いですが、後述する ヘッダーを読むかどうかを決める出発点 です。
2) ヘッダー:ピクセルを作るために必須の最小情報
シグネチャで「どのフォーマットか」を知ったら、次は通常ヘッダーです。ヘッダーはデコーダ(画像ローダ)がピクセルを復元するために必ず必要な情報を含みます。
代表的に次の情報が含まれるか、ヘッダーを通じてアクセス可能です。
- 横/縦サイズ:width, height
- 色表現方式:例)RGBか、透明度(アルファ)があるか
- 精度(ビット数):例)8ビット、16ビットなど
- データを読む方法:圧縮/エンコードの有無、必要な処理方式
重要なのはこの点です。
ピクセルデータは通常「そのまま読み取りにくい形」なので、ファイルはまずヘッダーに「読む方法」を入れておく。
ヘッダーが無いか破損していると、ピクセルデータが残っていても正常に解釈できません。
3) メタデータ:画像自体ではなく「画像に関する情報」
画像ファイルには「見える絵」以外に 付加情報 が入ることがあります。これはピクセルを作るために必ずしも必要ではないかもしれませんが、製品ではよく問題になることも有用です。
- 撮影時間、カメラ情報、方向(回転情報)
- 色空間関連情報
- プレビュー用の小さな画像(サムネイル)
- その他制作ツール、著作権表示など
開発観点でメタデータのポイントは単純です。
- あるかもしれないし、ないかもしれない。
- 正常動作に影響を与えることもある。(例:方向情報)
- セキュリティ/プライバシーの問題になることもある。(例:位置情報)
したがって「ピクセルだけ抜けば終わり」ではなく、システムによってはメタデータも一緒に扱う必要があります。
4) 画像データ:ほとんどは「圧縮/エンコードされた状態」で保存される
画像ファイルの目的は保存と送信です。したがって実際の画像データは通常以下のいずれかです。
- 無圧縮(稀または限定的):そのままピクセル値が保存される
- 圧縮/エンコード(ほとんど):サイズを減らすために変換された形で保存される
開発者が知っておくべきコアは次です。
ファイル内の画像データは「そのままピクセル配列」ではない可能性が非常に高い。通常はデコード処理を経てメモリ上でピクセルに変わる。
つまり、ファイルは保存に最適化され、メモリのピクセルバッファは処理に最適化されています。両者は形が違うのが当然です。
5) 「ファイル」と「メモリ」は別の姿を持つ
同じ画像を扱っても、開発者が遭遇する姿は二つあります。
- ディスクに保存された画像ファイルはストリーム:シグネチャ + ヘッダー/メタデータ + データが順序通りに並んだバイトの流れ。
- メモリに上がった画像はオブジェクト:width/height とピクセルバッファ(そして補助情報)を持つ構造化オブジェクトで、開発者が簡単にアクセスできる。
したがって処理フローは通常こうなります。
- ファイルの先頭を読み、形式を推定(シグネチャ)
- ヘッダーを読み「どう解凍するか」を決定
- データをデコードしメモリにピクセル形式で載せる
- その後でリサイズ/クロップ/フィルタなどを行う
この観点で見ると「画像ファイル」は単なる絵ではなく、解釈可能な構造を持つデータであることが明確になります。
締めくくり:『画像ファイルを読む』は構造を解釈する作業である
画像ファイルはフォーマットごとに細部は異なりますが、開発者の目線では共通して シグネチャ → ヘッダー → (任意)メタデータ → 画像データ という流れを持つ。 この順序は単なる慣例ではなく、ファイルを安全かつ一貫して解釈するための設計 に近い。
そして私たちがよく言う「画像を開く(open)」という行為は、実際には次を含む。
- ファイル先頭を読み 形式を識別
- ヘッダーを通じて 解釈規則を確保
- 必要ならメタデータまで考慮
- 最終的に画像データを メモリのピクセル形式へ復元
つまり、画像はピクセルだけで存在するのではなく、ピクセルを復元するための構造と規則を併せ持つファイル です。この構造を知れば、ライブラリが無い環境でも問題をより速く診断し、どの段階で壊れたか(識別/ヘッダー/デコード)を区別して対処できます。
次回予告
python-magicと Linux のfileコマンドがどのような関係にあり、これらのツールが「ファイルタイプ判別」をどう行うか整理します。- Pillow(PIL)で
open()、load()、verify()などのコアメソッドが実際にどんな差を生み、どの状況でどのメソッドを選択すべきかを扱います。
関連記事:
コメントはありません。