Django/Security 画像アップロード、無作為に受け取るとサーバーが壊れる:セキュリティと効率を両立する完全ガイド
ウェブサービスで画像アップロードは「常にある機能」として簡単に作れます。しかしアップロードエンドポイントは 外部データがサーバー内部に入る最も直接的な通路 であり、攻撃者にとっては 最も低コストで最大の被害を狙えるポイント です。(ウェブシェルアップロード、画像パーサー脆弱性、DoS など)
この記事は「セキュリティは偏執的に、リソースは経済的に」という一見矛盾した目標を 両方満たす 方法を整理します。核心はシンプルです。
- 検証段階ではできるだけ「読み込まない」(デコード禁止、ヘッダー/メタデータのみ)
- 保存段階では大胆に「再作成」(TranscodingでSanitizing)
アップロードセキュリティの本質:"信頼しない、できるだけ遅く信じる"

アップロードで信頼できるものはほとんどありません。
- ファイル名:ユーザーが変更する
- 拡張子:好きに変更する
- Content-Type:クライアントが送る
- ファイル内容:攻撃者が作る
したがって戦略は 2 つに収束します。
- 軽いコストで高速に除外(cheap checks)
- 最終保存物は常にサーバーが作る(server‑generated artifact)
よくある誤解:"確実に検査したいなら最後まで読み込むべき"
セキュリティをよくしたい開発者がよく犯すミスがあります。アップロード検証段階で以下のようなコードを入れます。
img = Image.open(file)
img.verify() # または img.load()
問題はこれが サーバーリソースを攻撃者に「前払い」で提供している 行為である点です。
なぜ危険なのか?
- 圧縮爆弾(Decompression Bomb)
表面上は数 MB だが、デコードすると数十 GB になるファイルが来る可能性があります。
load()は実際にピクセルをデコードし、メモリ/CPU を瞬時に枯渇させ DoS へとつながります。 - 不要な I/O
verify()はファイルを最後まで読む性質があり、I/O コストが大きく、後続処理では通常seek(0)/ 再オープンが必要です。
結論: アップロード「検証」段階でピクセルをデコードしないでください。 ヘッダー + メタデータ + 解像度制限だけで 1 次防御は十分に強力です。
防御は一発ではなく 3 段階:Defense in Depth
画像アップロードは「一行の if」で終わる問題ではありません。現実的なバランスを取るにはレイヤーを積む必要があります。
1 段階:拡張子は嘘だ — Magic Number で MIME 判別
profile.png という名前は何の意味もありません。ファイルの シグネチャ(Magic Number) を読み、実際のタイプを確認する必要があります。
- ファイル全体を
read()しないでください。先頭 1〜2KB で十分です。 - ライブラリ例:
python-magic(libmagic ベース)
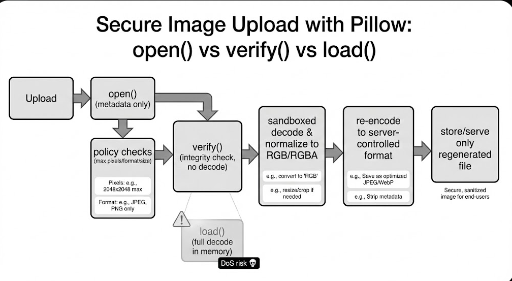
2 段階:Pillow は「開くだけ」でまだ安全 — Lazy Loading で解像度制限
Pillow の Image.open() は一般的に 即座にピクセルをロードせずヘッダーだけをパース します。この性質を利用して、デコード/メモリ爆弾を誘発する前に 解像度(ピクセル数)でブロック できます。
- チェックするもの:
width * height <= MAX_PIXELS - ポイント:
load()/verify()なしでsizeだけを見る
3 段階:最高の消毒は「新しく描く」 — Transcoding で Sanitizing
最も重要な原則です。
原本をそのまま保存しないでください。
画像にはメタデータ(EXIF)、プロファイル、スラックスペース、パーサートリックなど 「ピクセル以外の領域」 に奇妙なものが潜む可能性があります。逆に、ピクセルデータだけを抽出してサーバーが新フォーマットで再保存すれば、かなりの部分が自然に除去されます。
- 推奨:WebP(または AVIF/JPEG) でサーバーが再エンコードして保存
- 効果:Sanitizing + 容量最適化 + 一貫したフォーマットポリシー
実践実装:DRF Serializer(セキュリティ + メモリ経済性)
以下のコードは「検証段階でできるだけ読み込まず」「保存段階で再作成する」という哲学をそのまま取り入れています。
f.sizeは Django が既に知っているメタデータなので積極的に活用- Magic Number は 先頭だけ
- Pillow は
open()で 解像度だけ - 最終保存は Transcoding(WebP)
- 各段階で
seek(0)でファイルポインタを復元(失敗すると次の段階が壊れます)
from io import BytesIO
import magic
from PIL import Image, ImageOps, UnidentifiedImageError
from rest_framework import serializers
# ポリシー(サービスに合わせて調整)
MAX_SIZE = 5 * 1024 * 1024 # 5MB
MAX_PIXELS = 4_194_304 # 2048 * 2048 ≈ 4MP
ALLOWED_MIME = {"image/png", "image/jpeg", "image/webp"}
class SecureImageUploadSerializer(serializers.Serializer):
file = serializers.ImageField()
def validate_file(self, f):
# [1] サイズ制限:最も安価で高速なフィルタ
if f.size > MAX_SIZE:
raise serializers.ValidationError("ファイルサイズが大きすぎます。")
# [2] Magic Number で MIME 確認:拡張子/Content-Type を信用しない
f.seek(0)
head = f.read(2048) # 先頭だけ
f.seek(0)
mime = magic.from_buffer(head, mime=True)
if mime not in ALLOWED_MIME:
raise serializers.ValidationError("サポートされていないファイル形式です。")
# [3] 解像度制限:load/verify なしでヘッダーだけで size を確認
try:
with Image.open(f) as img:
w, h = img.size
if (w * h) > MAX_PIXELS:
raise serializers.ValidationError("画像解像度が大きすぎます。")
except UnidentifiedImageError:
raise serializers.ValidationError("有効な画像ではありません。")
except Exception:
raise serializers.ValidationError("画像検証中にエラーが発生しました。")
finally:
f.seek(0)
return f
def create(self, validated_data):
f = validated_data["file"]
# 最終保存物は常にサーバーが生成(Sanitizing)
try:
with Image.open(f) as img:
# EXIF 回転補正(モバイルアップロードで特に重要)
img = ImageOps.exif_transpose(img)
# 安全で一貫した色空間に正規化
if img.mode not in ("RGB", "RGBA"):
img = img.convert("RGB")
out = BytesIO()
img.save(out, format="WEBP", quality=85, method=6)
out.seek(0)
safe_bytes = out.getvalue()
# ここで safe_bytes をストレージに保存してください。
# - ファイル名は乱数化(UUID)
# - ディレクトリシャーディング(例:ab/cd/uuid.webp)
# - DB にはオリジナル名ではなくサーバー生成キーのみ保存
return safe_bytes
except Exception:
raise serializers.ValidationError("画像処理中にエラーが発生しました。")
"偏執的セキュリティ" vs "リソース経済性" のバランスを取る方法
ここで重要なバランス感覚はこれです。
検証段階で貪欲にならない
検証段階はトラフィックが最も多く、攻撃者がコストなしで繰り返し呼び出せる領域です。
ここで load() のような「高価な演算」を行うと、攻撃者がサーバーコストを自由に消費できます。
- ✅ サイズ制限 / ヘッダーベース MIME / 解像度制限
- ❌ ピクセルデコード強制 / ファイル全体読み込み / 複数再オープン
「本当に安全」は保存段階で作る
検証段階は「除外」の段階であり、保存段階は「標準化」の段階です。 保存段階でサーバーが 新しいバイトストリームを生成 するとセキュリティと運用が容易になります。
- フォーマット統一 → キャッシュ戦略/サムネイルパイプライン簡素化
- メタデータ整理 → 個人情報(EXIF GPS)除去にも有利
- 悪意あるペイロード挿入余地を縮小
さらに完璧にするためのポイント
- ファイル名は絶対に信頼しない、サーバーで生成(UUID 推奨)
- アップロードはアプリサーバーが直接受け取らない構造も検討 (大規模サービスなら presigned URL でオブジェクトストレージ直アップロード + 非同期検査/変換)
- 処理時間制限/ワーカー分離 画像変換は CPU を消費します。ウェブリクエスト‑レスポンス経路で長時間待たせず、ワーカー/キューへ分離するのも現実的選択です。
- ログ/メトリクス 拒否理由(MIME 不一致、解像度超過、サイズ超過)を集計すると攻撃/悪用パターンが早く見えます。
チェックリストまとめ
- メモリに全ファイルを載せない。
read()は先頭だけ、残りはストリーミング/ファイルオブジェクトベース。 - 拡張子/Content-Type を信用せず Magic Number で MIME 確認
- 検証段階で
load()/verify()でデコードせず解像度だけチェック - 原本を保存せず Transcoding でサーバーが新ファイルを生成
- ファイルポインタは各段階で
seek(0)で復元
アップロードセキュリティは「ユーザーを疑う心」から始まりますが、アップロード性能は「システムがどう動くかを理解する姿勢」から完成します。 どちらか一方だけを気にすると最終的に運用で壊れます。両方を同時に捉える構造で、アップロードポートを安全にしましょう。
関連ポストも確認してください

コメントはありません。