nginxで始める実践的ロードバランシングガイド
多くの開発者はnginxを「リバースプロキシ+静的ファイルサーバ」としてしか使いませんが、実際にはnginxは非常に強力なソフトウェアロードバランサです。 サーバーを自ら管理している開発者なら、nginxを上手く使うだけでトラフィックが集中した際にサービスの安定性と性能を大幅に向上させることができます。
この記事では初級〜中級開発者を対象に、以下の項目を一度にまとめて解説します。
- ロードバランシングの概念
- nginxでのロードバランシング設定方法
- アルゴリズム(ラウンドロビン、least_conn、ip_hash など)
- ヘルスチェック(Health Check)
- よく使うオプション
1. ロードバランシングとは何か?

ロードバランシング(load balancing) は簡単に言えば、
「複数のサーバーにリクエストを均等に分散させ、1台に過負荷がかからないようにする」
ということです。
なぜ必要なのか?
- トラフィックの急増に備える * 特定の時間にリクエストが集中しても、1台のサーバーが落ちないようにする。
- スケールアウト(拡張性) * サーバーを縦に(スペックアップ)する代わりに、複数台を横に増やして処理量を上げる。
- フェイルオーバー(高可用性) * 1台のサーバーが落ちても、他のサーバーへトラフィックを送ってサービスを継続する。
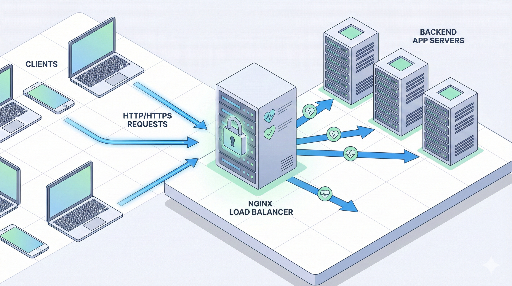
nginxはどこに位置するのか?
典型的な構成は次のようになります。
クライアント → nginx(ロードバランサ/リバースプロキシ) → 複数のアプリサーバー
ここでnginxはリクエストを受け取り、後ろにある複数のアプリサーバーのうち1台へ転送する役割を担います。
2. nginxロードバランシングの基本構造を理解する
nginx設定でロードバランシングの核となるのは大きく2つです。
- upstreamブロック: * 「バックエンドサーバープール」を定義
- server / locationブロック: * 受信したリクエストをどのupstreamへ送るかを定義
まずは最もシンプルな例を見てみましょう。
http {
upstream app_backend {
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://app_backend;
# プロキシのデフォルトヘッダー
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
この設定が意味すること
upstream app_backend10.0.0.101:3000と10.0.0.102:3000の2台を1つのプールにまとめるproxy_pass http://app_backend;- クライアントからのリクエストを
app_backendプールの1台へ転送 - ロードバランシングのアルゴリズムは、何も指定しない場合はデフォルトでラウンドロビンです。
3. ロードバランシングアルゴリズムの種類
nginxはさまざまな分散戦略を提供しています。状況に合わせて選択することが重要です。
3.1 基本:ラウンドロビン(round robin)
設定:何も書かないとデフォルト
upstream app_backend {
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
- 1回目のリクエスト → サーバー1
- 2回目のリクエスト → サーバー2
- 3回目のリクエスト → 再びサーバー1 …
メリット:単純でほとんどの場合に十分 デメリット:各サーバーの現在の負荷状況は考慮しない
3.2 least_conn(現在接続が最も少ないサーバーへ)
upstream app_backend {
least_conn;
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
- アクティブな接続数が最も少ないサーバーへ新しいリクエストを送る
- サービスごとに処理時間に大きな差がある場合(例:一部リクエストが長時間かかるAPI)に有効
推奨シナリオ
- 特定のリクエストは長時間かかり、他はすぐに終わるAPIサーバー
- サーバーのスペックは同じだが、リクエストパターンが不均一な場合
3.3 ip_hash(同じクライアント → 同じサーバーへ)
upstream app_backend {
ip_hash;
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
- クライアントIPをハッシュして常に同じサーバーへルーティング
- セッションスティッキーが必要な場合に簡単に利用可能 (サーバー側でセッションをメモリに保持しているレガシー構成でよく使われる)
メリット
- ユーザーセッションがサーバーメモリにある場合、同一ユーザーのリクエストが同じサーバーへ届く
デメリット
- サーバーを追加・削除するとハッシュが変わり、多くのユーザーのマッピングが変わる可能性がある
- クライアントの実際のIPを受け取れない場合(Cloudflare、ELB等)意味がない
3.4 重み(weight)ベースの分散
サーバーごとにスペックが異なる場合、より良いサーバーに多くのトラフィックを送ることができます。
upstream app_backend {
server 10.0.0.101:3000 weight=3;
server 10.0.0.102:3000 weight=1;
}
- サーバー1 : サーバー2 = 3 : 1 の比率でリクエストを分配
- スペックの良い新規サーバーを優先的に活用したいときに有効
4. ヘルスチェック(Health Check)と障害サーバー処理
ロードバランサが本当に賢くなるためには、障害サーバーを自動で除外する機能が重要です。
nginxオープンソース版では、パッシブヘルスチェック(passive health check)がデフォルトでサポートされています。
4.1 max_fails / fail_timeout
upstream app_backend {
server 10.0.0.101:3000 max_fails=3 fail_timeout=30s;
server 10.0.0.102:3000 max_fails=3 fail_timeout=30s;
}
max_fails=3- 連続して3回失敗したら、そのサーバーを異常とみなす
fail_timeout=30s- 30秒間はそのサーバーへトラフィックを送らない
- その後再度リクエストを送り、復旧していれば再び使用
「失敗」の基準は主に 502/503/504 レスポンス、接続失敗などです。
4.2 proxy_next_upstream
どの状況で次のサーバーへリクエストを転送するかを決められます。
location / {
proxy_pass http://app_backend;
proxy_next_upstream error timeout http_502 http_503 http_504;
}
- 指定したエラーが発生したら、次のサーバーへ再試行
- 過度な再試行は遅延を増やす可能性があるので、必要なケースのみ指定するのがベスト
5. 実践設定例:シンプルなWebサービスのロードバランシング
例として、Node.jsアプリサーバーを2台、3000番ポートで稼働させていると仮定します。
10.0.0.101:300010.0.0.102:3000
5.1 nginx設定例
http {
upstream app_backend {
least_conn;
server 10.0.0.101:3000 max_fails=3 fail_timeout=30s;
server 10.0.0.102:3000 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
server_name myservice.com;
# クライアント → nginx → Node.jsサーバーへプロキシ
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_read_timeout 60s;
proxy_connect_timeout 5s;
proxy_send_timeout 10s;
}
}
}
この設定でnginxをリロードすると、
myservice.comへのすべてのリクエストは → nginxが受け取り → 現在接続が少ないNode.jsサーバーへ転送- 特定サーバーが連続して失敗すると → 一定時間自動で除外
6. HTTPS(SSL)終了 + ロードバランシング
本番環境ではほぼ常にHTTPSを使用します。nginxをSSL終了(termination)のポイントとして使うパターンが最も一般的です。
http {
upstream app_backend {
least_conn;
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
server {
listen 443 ssl;
server_name myservice.com;
ssl_certificate /etc/letsencrypt/live/myservice.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/myservice.com/privkey.pem;
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
# HTTP → HTTPS リダイレクト
server {
listen 80;
server_name myservice.com;
return 301 https://$host$request_uri;
}
}
- クライアントとnginxの間:HTTPS
- nginxとアプリサーバーの間:HTTP(内部ネットワークなら通常こうする)
7. セッション問題:スティッキーセッションは本当に必要か?
昔はサーバー側でメモリにセッションを保存するケースが多く、 同じユーザーは同じサーバーへ送る必要がありました。
この場合、nginxでは ip_hash で簡単に解決できますが、最近は以下のような方法が主流です。
- Redis 等の外部ストレージにセッションを保存
- JWT ベースでサーバーをステートレスに構成
可能ならアプリケーションレベルで状態を排除し、ロードバランサは純粋にトラフィック分散だけに専念する方が運用・拡張に有利です。
8. よく使うチューニングポイント
8.1 keepalive設定
バックエンドサーバーとの接続を再利用すると性能が向上します。
upstream app_backend {
least_conn;
server 10.0.0.101:3000;
server 10.0.0.102:3000;
keepalive 32;
}
server {
location / {
proxy_pass http://app_backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
keepalive 32;- 各ワーカープロセスでバックエンドへ最大32個の keepalive 接続を維持
- 毎リクエストで TCP 接続を新規に確立しないため、レイテンシと負荷が減少
8.2 バッファ & タイムアウト
応答が大きい場合やバックエンドが遅い場合、バッファとタイムアウト設定も重要です。
location / {
proxy_pass http://app_backend;
proxy_buffering on;
proxy_buffers 16 16k;
proxy_busy_buffers_size 64k;
proxy_read_timeout 60s;
proxy_send_timeout 60s;
}
proxy_read_timeoutが短すぎると → バックエンドが少し遅れても 504 Gateway Timeout が発生しやすい- 実際のトラフィックパターンとバックエンド性能に合わせて調整が必要
9. nginxロードバランシング導入戦略(段階別)
既にサービスが稼働していて、1台のサーバーにすべてを乗せている場合、以下のように段階的に拡張する方法をおすすめします。
- 第1段階:nginxをリバースプロキシとして導入 * クライアント → nginx → 既存単一アプリサーバー * SSL終了、キャッシュ、静的ファイル配信を活用
- 第2段階:アプリサーバーを複製し upstream を構成
* 既存サーバーを複製または新規サーバーを立ち上げ、データ同期
*
upstreamブロックに2台を入れロードバランシング開始 - 第3段階:ヘルスチェック + モニタリング
*
max_fails、fail_timeout、proxy_next_upstreamを設定 * ログ/メトリクス収集(例:Prometheus + Grafana、ELK 等)を導入 - 第4段階:アルゴリズムと詳細チューニング
* トラフィックパターンに応じて
least_connやweightを活用 * keepalive、バッファ、タイムアウトで性能向上
まとめ
nginxを「ただのリバースプロキシ」として使うだけではもったいないほど、ロードバランシング機能が充実しています。
- upstream ブロックでサーバープールを定義
- 状況に合わせた ロードバランシングアルゴリズム を選択(round robin / least_conn / ip_hash / weight)
- ヘルスチェック + 再試行ポリシー で障害サーバーを自動除外
- HTTPS終了 + バックエンドプロキシ でセキュリティと性能を同時に確保
これらを理解し実装すれば、トラフィックが増えても1台のサーバーで十分か? という疑問に対し、nginxで一歩上のインフラを自ら構築できるようになります。


コメントはありません。