La perspectiva del desarrollador sobre los archivos de imagen: la estructura común a todos los formatos
Para el usuario, un archivo de imagen es simplemente una “imagen”. Para el desarrollador, es un conjunto de datos binarios que, además, incluye la información necesaria para interpretarlo.
En este artículo, dejaremos de lado las particularidades de JPG/PNG/WebP y nos centraremos en la estructura que comparten todos los formatos. Se minimizará el uso de términos y se explicará únicamente a partir de la estructura.
Un archivo de imagen no es un "montón de píxeles", sino un "bloque de bytes con reglas"

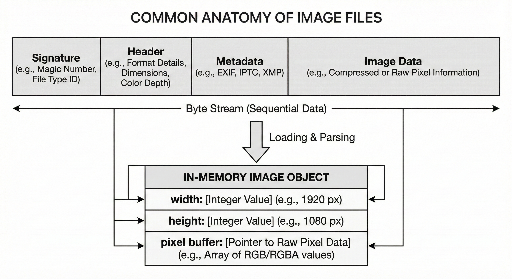
La esencia de un archivo de imagen suele estar compuesta por tres partes:
- Zona de identificación: indica el formato del archivo.
- Información de interpretación: tamaño, modo de color, etc.
- Datos de imagen reales: normalmente comprimidos o codificados.
Aunque los nombres y la disposición varían, la estructura general sigue este patrón.
1) Firma de archivo: la primera pista de "qué es este archivo"
La mayoría de los archivos de imagen comienzan con un patrón de bytes único. Es más fiable que la extensión.
- La extensión puede cambiarse libremente.
- La firma, en cambio, es difícil de falsificar.
Por eso, los desarrolladores determinan el tipo de archivo leyendo los primeros bytes, no el nombre.
La firma suele ser breve, pero es el punto de partida para decidir si se leerá el encabezado.
2) Encabezado: la información mínima necesaria para reconstruir los píxeles
Una vez identificado el formato, se lee el encabezado. Este contiene los datos esenciales que el decodificador necesita para reconstruir los píxeles.
Entre la información típica se incluyen:
- Ancho y alto: width, height
- Modo de color: RGB, RGBA, etc.
- Precisión: 8 bits, 16 bits, etc.
- Método de lectura: compresión, codificación, etc.
El encabezado es crucial porque los datos de imagen suelen estar en un formato que no se puede interpretar directamente sin decodificación.
3) Metadatos: información sobre la imagen, no la imagen en sí
Los archivos de imagen pueden contener datos adicionales que no son necesarios para la visualización, pero que pueden ser útiles o problemáticos.
- Fecha de captura, información de la cámara, orientación
- Información de espacio de color
- Miniatura para vista previa
- Herramientas de creación, derechos de autor, etc.
Desde el punto de vista del desarrollador:
- Pueden estar presentes o ausentes.
- Pueden afectar el funcionamiento (por ejemplo, la orientación).
- Pueden plantear problemas de seguridad o privacidad (por ejemplo, GPS).
Por lo tanto, en algunos sistemas es necesario procesar los metadatos junto con los píxeles.
4) Datos de imagen: la mayoría se almacena en forma comprimida o codificada
El objetivo de un archivo de imagen es almacenar y transferir datos.
- Sin compresión (raramente): los valores de píxel se guardan tal cual.
- Con compresión/codificación (común): se guardan en un formato reducido.
El punto clave es que los datos de imagen dentro del archivo no suelen ser un arreglo de píxeles directo; se requiere decodificación.
5) "Archivo" y "memoria" son diferentes
El mismo contenido visual se presenta de dos maneras al desarrollador:
- Archivo en disco: una secuencia de bytes (firma + encabezado/metadatos + datos).
- Objeto en memoria: una estructura con width/height, buffer de píxeles y datos auxiliares.
El flujo típico es:
- Leer la firma para identificar el formato.
- Leer el encabezado para decidir cómo decodificar.
- Decodificar los datos y cargar los píxeles en memoria.
- Aplicar operaciones posteriores (redimensionar, recortar, filtrar).
Desde esta perspectiva, un "archivo de imagen" es más que una imagen; es un conjunto de datos estructurados.
Conclusión: leer un archivo de imagen es interpretar su estructura
Aunque cada formato tiene detalles específicos, la secuencia común es: firma → encabezado → (opcional) metadatos → datos de imagen. Esta secuencia no es arbitraria; está diseñada para interpretar archivos de manera segura y consistente.
Cuando decimos "abrir una imagen", en realidad estamos:
- Identificando el formato.
- Obteniendo las reglas de interpretación.
- Considerando los metadatos si es necesario.
- Decodificando los datos para obtener los píxeles en memoria.
Conocer esta estructura permite diagnosticar problemas rápidamente, incluso sin bibliotecas especializadas.
Próximo artículo
- Analizaremos la relación entre
python-magicy el comandofilede Linux, y cómo determinan el tipo de archivo. - Exploraremos los métodos
open(),load(),verify()de Pillow (PIL) y cuándo usar cada uno.
Más lecturas:
No hay comentarios.