python-magic: Der praktischste Weg, sich auf den Dateiinhalt statt auf die Dateiendung zu verlassen
Wenn ein Server eine Bild-Upload-Funktion hat, tauchen irgendwann solche Anforderungen auf.
- „Es wurde als
.pnghochgeladen… ist es wirklich ein PNG?“ - „Zuerst muss entschieden werden, ob die Datei ein Bild oder ein Dokument ist.“
- „Bevor ich einen externen Parser (Pillow/OpenCV) verwende, möchte ich zumindest den Typ prüfen.“
Der beste Ausgangspunkt ist hier nicht die Dateiendung, sondern der Dateiinhalt.
Und das Tool, das die „inhaltbasierte Erkennung“ am einfachsten bereitstellt, ist python-magic.
Was macht python-magic?

python-magic ist ein Wrapper, der die C-Bibliothek libmagic in Python nutzbar macht. libmagic untersucht Merkmale wie den Header (die ersten Bytes) einer Datei, um deren Typ zu identifizieren. Diese Funktion wird auch von dem Unix-Befehl file bereitgestellt.
Kurz gesagt:
file(Linux-Befehl) = „Schnittstelle, die im Terminal verwendet wird“libmagic= „Kern-Engine (Erkennungslogik)“python-magic= „Dünner Wrapper, der libmagic aus Python aufruft“
In diesem Beitrag konzentrieren wir uns auf python-magic und erklären strukturiert, wie die Engine Dateitypen erkennt.
Wie funktioniert die Kern-Engine (libmagic)?
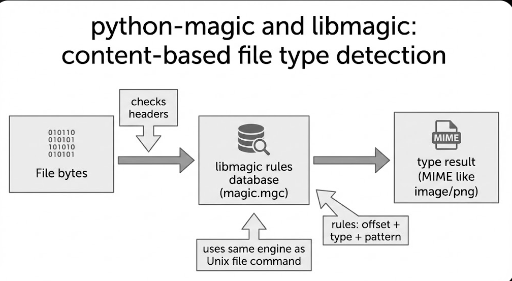
Die Essenz von libmagic ist einfach.
„Es liest eine Datenbank mit Regeln zur Dateityp-Erkennung, prüft die Datei-Bytes gemäß diesen Regeln und zieht die plausibelste Schlussfolgerung.“
Hierbei ist die Datenbank die Magic-Datenbank (Magic-Pattern-DB), die zusammen mit file/libmagic verwendet wird. Sie wird üblicherweise als kompiliertes Format (magic.mgc) im System installiert.
1) Die „Magic-Datei“ ist eine Sammlung von Regeln
Diese Regeln bestehen im Wesentlichen aus folgenden Elementen:
- Wo zu schauen (Offset: Position im Dateibuffer)
- Wie zu lesen (Typ: Byte/String/Integer usw.)
- Was zu vergleichen (erwarteter Wert/Pattern)
- Welche Schlussfolgerung (Nachricht/MIME usw.)
Die Dokumentation von file beschreibt die „Magic-Patterns“ ebenfalls. Die Regeln werden Zeile für Zeile getestet (Offset/Typ/Wert/Nachricht) und bei Übereinstimmung in eine hierarchische Struktur von Untertests überführt.
Wer mehr über den Linux-Befehl file erfahren möchte, kann den folgenden Link nutzen.
2) Die Regel-Datenbank hat eine „Textquelle“ und ein „kompiliertes Ergebnis“
Die Magic-Datenbank kann ursprünglich aus lesbaren Text-Fragmenten bestehen, wird aber für die Performance oft als kompilierte Binär-DB (.mgc) bereitgestellt.
3) Letztlich geht es darum, „statt der Endung den Inhalt zu prüfen“
file ist seit langem ein Typ-Schätzer, der den Inhalt statt der Endung betrachtet. python-magic bringt diese Philosophie in eine Zeile Python-Code.
Wie benutzt man python-magic?
Es gibt zwei typische Anwendungsfälle.
1) MIME-Typ abrufen (am praktischsten)
Nützlich für Upload-Verarbeitung, Routing, Logging/Monitoring.
import magic
mime = magic.from_file("upload.bin", mime=True)
print(mime) # z. B.: image/png
python-magic liefert die Dateityp-Erkennung auf Basis von libmagic, wie es auch in der offiziellen Dokumentation beschrieben ist.
2) Direkt aus Bytes erkennen (vorteilhaft für Upload-Streams)
Bevor die Datei auf die Festplatte geschrieben wird, möchte man oft nur einen Teil der hochgeladenen Bytes prüfen.
import magic
with open("upload.bin", "rb") as f:
head = f.read(4096)
mime = magic.from_buffer(head, mime=True)
print(mime)
(Die Puffer-Erkennung eignet sich besonders als „erste Filterstufe vor dem Speichern“.)
Wo ist es aus Entwicklersicht nützlich?
1) Erste Verteidigungslinie bei Upload-Validierung
- Nicht nur anhand der Endung unterscheiden
- Mindestens prüfen, ob die Datei als Bild verarbeitet werden kann
2) Verzweigungspunkte in der Verarbeitungspipeline
- Bei Bildern: in die Resize/Thumbnail-Pipeline
- Bei PDF/ZIP: in einen anderen Worker
- Unbekannte Typen: isolieren/ablehnen/weitere Prüfung
3) Kosten senken, bevor ein „schwerer Decoder“ aufgerufen wird
Decoder wie Pillow sind mächtig, aber ihr Aufruf kostet Speicher/CPU und erhöht die Angriffsfläche. python-magic hilft, vorher zu entscheiden, ob ein solcher Aufruf sinnvoll ist.
Wichtiger Real-World-Check: libmagic ist ein Schätzungs-/Erkennungs-Tool. Für eine sichere Erkennung (z. B. Blockierung bösartiger Payloads) sind zusätzliche Prüfungen (Whitelist, Größenbeschränkung, Sandbox-Decodierung) nötig.
Fazit: python-magic ist die leichteste Möglichkeit, Dateityp-Erkennung in Code zu bringen
python-magic liefert nicht die Bildverarbeitung selbst, sondern sagt schnell, wie die Datei behandelt werden soll.
- Engine: libmagic (wie
file) - Erkennungs-Methode: „Regel-DB + Byte-Prüfung“
- In der Praxis: besonders nützlich für Upload-Validierung, Routing und Kosten-Reduktion
Wenn man diese Technik beherrscht, kann man selbst in Umgebungen ohne umfangreiche Bibliotheken eine robuste „Erkennung → Verzweigung → Sicherheits-Schicht“ aufbauen.
Vorschau des nächsten Beitrags
- Wir werden die Methoden
open(),load()undverify()von Pillow (PIL) untersuchen, was sie garantieren, wann welche Methode eingesetzt wird und wie sie funktionieren.
Weitere Artikel
Es sind keine Kommentare vorhanden.