89/100
Wie Entwickler eine Bilddatei sehen: Die Struktur hinter dem Bild
Aus Nutzersicht ist eine Bilddatei einfach „ein Bild“. Aus Entwicklersicht ist sie ein Binärdatenpaket, das zusätzlich die Regeln enthält, wie diese Bytes zu interpretieren sind.
In diesem Beitrag lassen wir die formatspezifischen Eigenheiten von JPG/PNG/WebP beiseite und konzentrieren uns auf die Strukturen, die in praktisch allen Bildformaten wiederkehren. Wir halten die Terminologie bewusst knapp und erklären das Thema ausschließlich aus struktureller Sicht.
Eine Bilddatei ist kein „Pixelhaufen“, sondern eine „Bytefolge mit Regeln“

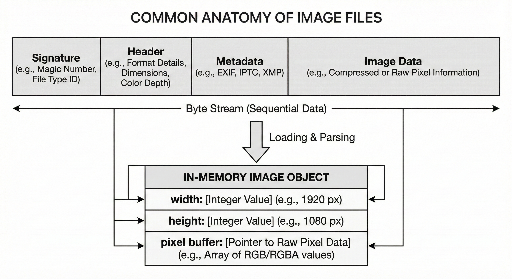
Der Kern einer Bilddatei besteht meist aus drei Teilen:
- Identitätsbereich – zeigt, um welches Format es sich handelt.
- Interpretationsdaten – enthalten Größe, Farbraum/Modell und weitere Hinweise zum Dekodieren.
- Bilddaten – liegen typischerweise komprimiert oder anderweitig codiert vor.
Bezeichnungen und Reihenfolge unterscheiden sich je nach Format, aber das Grundgerüst bleibt erstaunlich konstant.
1) Dateisignatur: Der erste Hinweis auf die Identität der Datei
Die meisten Bilddateien beginnen mit einem eindeutigen Byte-Muster – der Signatur. Sie ist ein verlässlicherer Indikator als die Dateiendung.
- Dateiendungen lassen sich beliebig ändern.
- Eine Signatur ist dagegen schwer „nachzuahmen“, wenn die Datei nicht tatsächlich dem Format folgt.
Darum bestimmen Entwickler den Typ einer Datei, indem sie die ersten Bytes prüfen – nicht den Dateinamen.
Die Signatur umfasst oft nur wenige Bytes, dient aber als Startpunkt dafür, ob und wie der Header gelesen werden soll.
2) Header: Die Mindestinformationen, um Pixel rekonstruieren zu können
Sobald das Format feststeht, folgt der Header. Er enthält die Informationen, die ein Decoder braucht, um aus den gespeicherten Daten wieder ein Pixelraster aufzubauen.
Typische Header-Felder sind:
- Breite/Höhe
- Farbmodell (z. B. RGB, ggf. mit Alpha-Kanal)
- Bittiefe (8-Bit, 16-Bit usw.)
- Kompressions-/Codierverfahren und ggf. weitere Verarbeitungsschritte
Der entscheidende Punkt: Die Bilddaten sind meist nicht direkt als Pixel lesbar. Der Header liefert die Regeln, wie sie zu interpretieren sind. Fehlt ein gültiger Header, kann selbst intakter Dateninhalt unbrauchbar sein.
3) Metadaten: Informationen über das Bild – nicht das Bild selbst
Neben der sichtbaren Darstellung können Bilddateien zusätzliche Informationen tragen, die für die Darstellung nicht zwingend nötig sind, in der Praxis aber nützlich oder problematisch sein können.
Beispiele:
- Aufnahmezeitpunkt, Kameraeinstellungen, Ausrichtung (Orientation)
- Farbraum-Informationen
- Eingebettete Vorschau (Thumbnail)
- Autor, Copyright, Tool-Metadaten
Aus Entwicklersicht sind Metadaten:
- Optional
- Mitunter relevant für die korrekte Darstellung (z. B. Orientation)
- Ein möglicher Datenschutzfaktor (z. B. Standortdaten)
Darum reicht es je nach System nicht, nur „Pixel zu extrahieren“ – Metadaten müssen ggf. mitbehandelt werden.
4) Bilddaten: Meist komprimiert oder codiert gespeichert
Eine Bilddatei ist für Speicherung und Übertragung optimiert. Deshalb liegen die Bilddaten häufig in einer komprimierten oder codierten Form vor.
Typische Speicherarten:
- Unkomprimiert (selten bzw. eingeschränkt) – rohe Pixelwerte
- Komprimiert/Codiert (am häufigsten) – zur Reduktion der Dateigröße
Die Kernaussage für Entwickler:
Was in der Datei liegt, ist selten ein rohes Pixel-Array. Um Pixel im Speicher zu erhalten, muss dekodiert werden.
Dateien sind auf Speicherplatz optimiert, Pixelpuffer im RAM auf Verarbeitung.
5) „Datei“ vs. „Speicherrepräsentation“
Dasselbe Bild begegnet Entwicklern typischerweise in zwei Gestalten:
- Auf der Festplatte – ein Bytestrom: Signatur + Header/Metadaten + Daten.
- Im Speicher – ein Objekt mit Breite, Höhe, Pixelpuffer und optionalen Zusatzinfos.
Der übliche Ablauf sieht so aus:
- Anfang der Datei lesen und Format erkennen (Signatur).
- Header lesen und Dekodierregeln bestimmen.
- Daten dekodieren und in einen Pixelpuffer im Speicher überführen.
- Danach Skalieren, Zuschneiden, Filtern usw.
Aus dieser Perspektive ist eine Bilddatei nicht nur ein „Bild“, sondern ein strukturiertes, interpretierbares Datenset.
Fazit: Eine Bilddatei zu lesen heißt, ihre Struktur zu interpretieren
Auch wenn die Details je nach Format variieren, kann man sich auf die gemeinsame Sequenz verlassen: Signatur → Header → (optional) Metadaten → Bilddaten. Diese Reihenfolge ist kein Zufall, sondern ermöglicht eine sichere und konsistente Interpretation.
Wenn wir sagen, wir „öffnen ein Bild“, tun wir eigentlich Folgendes:
- Format anhand der Signatur identifizieren
- Dekodierregeln aus dem Header gewinnen
- Metadaten bei Bedarf berücksichtigen
- Bilddaten in einen Pixelpuffer im Speicher rekonstruieren
Wer diese Struktur versteht, kann Probleme schneller eingrenzen – auch ohne fertige Bibliothek – und unterscheiden, ob es um Erkennung, Header oder Dekodierung geht.
Ausblick auf den nächsten Beitrag
- Wie
python-magicund das Linux-Toolfilezusammenhängen und Dateitypen erkennen. - Die praktischen Unterschiede zwischen
open(),load()undverify()in Pillow (PIL) und wann man welche Methode nutzen sollte.
Weitere Artikel:
Es sind keine Kommentare vorhanden.