89/100
NumPy für Einsteiger in Deep Learning: Warum du es vor PyTorch lernen solltest
Warum Einsteiger in Deep Learning zuerst NumPy lernen sollten

In vielen Büchern und Kursen zu Deep Learning tauchen Frameworks wie PyTorch oder TensorFlow sehr früh auf. Doch sobald man selbst ein Modell baut, kommen oft Fragen wie:
- „Was ist eigentlich ein Tensor?“
- „Warum bekomme ich einen Shape-Fehler, obwohl die Dimensionen zu passen scheinen?“
- „Ich dachte, ich könnte die Batches einfach so zusammenfügen …“
Diese Verwirrung entsteht häufig, wenn man NumPy nicht ausreichend verstanden hat und direkt mit einem Deep-Learning-Framework startet.
- Ein PyTorch-
Tensorist konzeptionell sehr nah an NumPysndarray. - Datenvorverarbeitung, Batch-Erstellung und statistische Berechnungen verlangen weiterhin ein NumPy-orientiertes Denken.
Wenn du Deep Learning wirklich verstehen willst, ist NumPy ein nahezu unverzichtbares Fundament.
Was ist NumPy?
NumPy (Numerical Python) ist eine Bibliothek für schnelle numerische Berechnungen in Python.
Wichtige Stichworte:
- Mehrdimensionale Arrays (
ndarray): Grundlage für Vektoren, Matrizen und Tensoren - Vektorisierte Operationen: Große Datenmengen ohne
for-Schleifen verarbeiten - Broadcasting: Arrays mit unterschiedlichen Formen automatisch passend ausrichten
- Lineare Algebra: Matrixmultiplikation, Transponieren, Invertieren usw.
- Zufallszahlen/Random-Modul: Sampling, Normalverteilungen, zufällige Initialisierung
Fast alle Formeln in Deep Learning laufen auf Vektor- und Matrixoperationen hinaus. Deshalb kann man NumPy durchaus als eine Art „Sprache“ für Deep Learning sehen.
Python-Listen vs. NumPy-Arrays
Hier ein kurzer Vergleich zwischen Python-Listen und NumPy-Arrays:
# Python-Listen
A = [1, 2, 3, 4]
B = [10, 20, 30, 40]
# Listen-Addition
print(A + B)
# Ausgabe: [1, 2, 3, 4, 10, 20, 30, 40] (Verkettung)
Bei Listen bedeutet + Verkettung, nicht elementweise Addition.
import numpy as np
A = np.array([1, 2, 3, 4])
B = np.array([10, 20, 30, 40])
print(A + B)
# Ausgabe: [11 22 33 44] (elementweise Addition)
Bei NumPy-Arrays führt + die erwartete elementweise Operation aus. Genau diesem Stil folgen auch Tensoren in Deep-Learning-Frameworks.
Vektorisierung: Weniger Schleifen, Code wie Formeln
In Deep-Learning-Code wird oft geraten, for-Schleifen zu vermeiden und stattdessen Vektorisierung zu nutzen.
Beispiel: Alle Elemente quadrieren.
Python-Liste + for-Schleife
data = [1, 2, 3, 4, 5]
squared = []
for x in data:
squared.append(x ** 2)
print(squared) # [1, 4, 9, 16, 25]
NumPy-Vektorisierung
import numpy as np
data = np.array([1, 2, 3, 4, 5])
squared = data ** 2
print(squared) # [ 1 4 9 16 25]
- Kürzerer Code
- Mathematischer und leichter zu lesen
- Intern in C implementiert → deutlich schneller
PyTorch- und TensorFlow-Tensoren nutzen denselben vektorisierten Ansatz.
Broadcasting: Rechnen trotz unterschiedlicher Formen
Broadcasting ist eine Regel, die Arrays mit unterschiedlichen Formen automatisch kompatibel macht.
Beispiel: Eine Konstante zu jedem Sample addieren.
import numpy as np
x = np.array([[1, 2, 3],
[4, 5, 6]]) # shape: (2, 3)
b = np.array([10, 20, 30]) # shape: (3,)
y = x + b
print(y)
# [[11 22 33]
# [14 25 36]]
x hat die Form (2, 3), b die Form (3,). NumPy behandelt b so, dass es auf jede Zeile angewendet werden kann (effektiv (1, 3) → (2, 3)).
PyTorch verhält sich genauso:
import torch
x = torch.tensor([[1, 2, 3],
[4, 5, 6]])
b = torch.tensor([10, 20, 30])
y = x + b
print(y)
Wenn du Broadcasting in NumPy verstehst, wirkt das Arbeiten mit PyTorch-Tensoren wesentlich natürlicher.
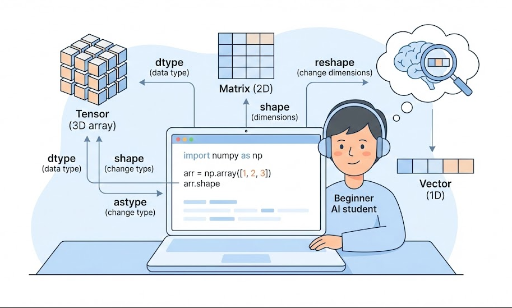
Vektor, Matrix, Tensor: Deep Learning in NumPy ausdrücken
Im Deep Learning entsprechen zentrale Konzepte in NumPy typischerweise:
- Vektor: 1D-Array →
shape: (N,) - Matrix: 2D-Array →
shape: (M, N) - Tensor: 3D oder höher
Beispiel: Bild-Batch
batch_size = 32, Graustufenbild 28×28 →shape: (32, 28, 28)
Beispiel: einfache Matrixmultiplikation
import numpy as np
# Eingabe-Vektor (3 Features)
x = np.array([1.0, 2.0, 3.0]) # shape: (3,)
# Gewichtsmatrix (3 → 2)
W = np.array([[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6]]) # shape: (2, 3)
# Matrixmultiplikation: y = W @ x
y = W @ x
print(y) # [1.4 3.2]
Das entspricht im Kern einer einfachen linearen Schicht. In PyTorch:
import torch
x = torch.tensor([1.0, 2.0, 3.0]) # shape: (3,)
W = torch.tensor([[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6]]) # shape: (2, 3)
y = W @ x
print(y)
Form und Bedeutung sind nahezu identisch. Wer NumPy-Matrixoperationen beherrscht, versteht Deep-Learning-Formeln oft deutlich schneller.
Wie hängen NumPy und PyTorch zusammen?
1. Tensor und ndarray sind „verwandt“
- Beide bieten n-dimensionale Arrays und vektorisierte Operationen.
shape,reshape,transpose,sum,meanheißen und funktionieren sehr ähnlich.
Darum verwenden viele NumPy als Übungsumgebung, um PyTorch-Tensoren besser zu verstehen.
2. Datenvorverarbeitung bleibt meist NumPy-Stil
In Deep-Learning-Projekten ist es üblich:
- CSV, Bilder oder Logs einzulesen
- in numerische Form zu bringen
- zu normalisieren/standardisieren, zu slicen, zu shuffeln und zu batchen
Das passiert oft mit NumPy + pandas.
import numpy as np
import torch
np_data = np.random.randn(100, 3) # 100 Samples, 3 Features
tensor_data = torch.from_numpy(np_data).float()
print(tensor_data.shape) # torch.Size([100, 3])
Umgekehrt wandelt man Tensoren häufig wieder in NumPy um:
y = tensor_data.mean(dim=0)
y_np = y.detach().cpu().numpy()
In der Praxis wechseln viele Workflows ständig zwischen NumPy und PyTorch.
3. GPU-Rechnen: PyTorch, Verständnis/Debugging: NumPy
- PyTorch-Tensoren laufen auf der GPU (CUDA) und unterstützen Autograd.
- NumPy läuft auf der CPU, ist dafür aber einfacher für kleine Experimente.
Typischer Ansatz:
- Idee oder Formel in NumPy klein testen
- danach in PyTorch für Training und GPU übertragen
Häufige NumPy-Muster in Deep Learning
1. Zufällige Initialisierung & Rauschen hinzufügen
import numpy as np
W = np.random.randn(3, 3) * 0.01
x = np.array([1.0, 2.0, 3.0])
noise = np.random.normal(0, 0.1, size=x.shape)
x_noisy = x + noise
2. Daten normalisieren (Mittelwert 0, Standardabweichung 1)
X = np.random.randn(100, 3) * 10 + 50
mean = X.mean(axis=0)
std = X.std(axis=0)
X_norm = (X - mean) / (std + 1e-8)
Diese Normalisierung kann die Stabilität und oft auch die Leistung des Trainings beeinflussen.
3. One-Hot-Encoding
num_classes = 4
labels = np.array([0, 2, 1, 3])
one_hot = np.eye(num_classes)[labels]
print(one_hot)
4. Batches aufteilen
X = np.random.randn(100, 3)
batch_size = 16
for i in range(0, len(X), batch_size):
batch = X[i:i+batch_size]
# Hier würde man batch ins Modell geben
Das entspricht inhaltlich dem Konzept von PyTorchs DataLoader.
Worauf du beim Lernen von NumPy achten solltest
Für Deep Learning reicht es meist, diese Bereiche zu beherrschen:
ndarray-Basics
-
np.array,dtype,shape,reshape,astype2. Indexierung & Slicing -
x[0],x[1:3],x[:, 0],x[:, 1:3] -
Boolesche Indexierung:
x[x > 0]3. Grundlegende Operationen -
+,-,*,/,**, Vergleiche -
np.sum,np.mean,np.max,np.min,axis4. Lineare Algebra -
@odernp.dot, Transponieren mitx.T5. Broadcasting -
Muster wie
(N, D) + (D,),(N, 1)usw. 6. Zufallsfunktionen -
np.random.randn,np.random.randint,np.random.permutation7. Anbindung an PyTorch -
torch.from_numpy,tensor.numpy()
Beherrschst du das, wirst du viele Tensor-Operationen in PyTorch deutlich intuitiver verstehen.
Fazit: NumPy ist eine Art „Grammatik“ für Deep Learning
Zusammengefasst:
- NumPy liefert n-dimensionale Arrays für numerische Berechnungen.
- Ein PyTorch-
Tensorist praktisch die Deep-Learning-Variante desndarray. -
Wer Vektorisierung, Broadcasting und lineare Algebra in NumPy beherrscht, profitiert direkt:
-
weniger Shape-Fehler
- Formeln aus Papern leichter in Code übersetzen
- Datenvorverarbeitung und Analyse werden einfacher
Wenn du Deep Learning nicht nur als Framework-Anwendung, sondern aus einer mathematisch/array-orientierten Perspektive verstehen willst, ist NumPy ein idealer Einstieg.




Es sind keine Kommentare vorhanden.