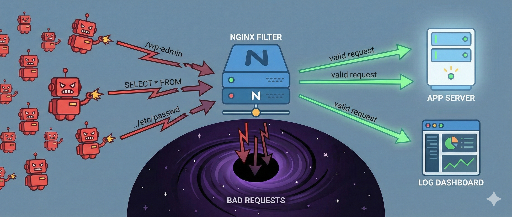
互聯網是不斷變化和擴展的巨大資訊海洋。網頁爬蟲(Web Crawler),通常被稱為機器人(Bot)的自動化程序,對於探索和收集這些龐大數據發揮著重要作用。這些機器人遊覽網頁以索引資訊,收集數據,並提供各種服務,是網絡生態系統的重要成員。然而,並不是所有的機器人對網頁都有益,某些有害的機器人也可能對網站造成損害或被惡意利用。
在本文中,我們將探討在互聯網上常見的著名機器人的種類和特徵,如何區分有益的機器人和有害的機器人,以及有效保護網站免受有害機器人侵害的方法。
網頁上常見的著名機器人(有益機器人)

大多數的網頁流量是由機器人而非人類產生的,其中最重要和有益的機器人有以下幾種:
1. 搜索引擎機器人(Search Engine Bots)
最普遍和重要的機器人。它們爬行網頁以收集內容,並將其添加到搜索引擎索引中,以幫助用戶尋找資訊。
-
Googlebot(Google): Google的代表性網頁爬蟲。它爬行幾乎所有的網頁,更新搜索結果,並向Google服務(地圖、新聞等)提供數據。
User-Agent顯示為Googlebot或Mediapartners-Google等。 -
Bingbot(Microsoft Bing): 微軟的Bing搜索引擎爬蟲。
User-Agent顯示為Bingbot。 -
Baidu Spider(Baidu): 中國主要搜索引擎Baidu的爬蟲。如果目標是中國市場,Baidu Spider的訪問也非常重要。
User-Agent顯示為Baiduspider。 -
Yandex Bot(Yandex): 俄羅斯主要搜索引擎Yandex的爬蟲。
User-Agent顯示為YandexBot。 -
Yeti(Naver): 韓國Naver的主要搜索引擎爬蟲。負責收集針對韓國市場的搜索結果,
User-Agent顯示為Yeti。
2. 社交媒體機器人(Social Media Bots)
在社交媒體上分享鏈接時,用於生成該鏈接的預覽(標題、描述、圖片)。
-
Facebook External Hit(Facebook): 在Facebook上分享鏈接時提取頁面資訊。
User-Agent顯示為facebookexternalhit。 -
Twitterbot(Twitter/X): 在Twitter(X)上生成鏈接預覽。
User-Agent顯示為Twitterbot。 -
Slackbot(Slack): 在Slack上分享鏈接時生成預覽。
User-Agent顯示為Slackbot。
3. 監控/分析機器人(Monitoring/Analytics Bots)
用於監控網站狀態、性能和安全漏洞等,或進行流量分析。
-
UptimeRobot, Pingdom: 監控網站正常運行時間,並在網站停機時發送通知。
-
網站爬蟲(Screaming Frog, Ahrefsbot, SemrushBot等): SEO工具分析網站,以尋找SEO改進點或收集競爭對手分析數據。
User-Agent中包含工具名稱。 -
Ahrefsbot(Ahrefs): Ahrefs是上述強大的SEO分析爬蟲之一,Ahrefsbot是互聯網上最活躍的商業爬蟲。收集網站的反向鏈接、關鍵字排名、有機流量等海量SEO數據,並提供給Ahrefs服務用戶。它特別廣泛地爬行互聯網以構建反向鏈接數據庫,因此在網站伺服器日誌中是僅次於
Googlebot最常見的爬蟲之一。User-Agent顯示為AhrefsBot。
區分有害的機器人和有益的機器人

機器人流量對網站的影響主要取決於機器人的目的和行為方式。有害機器人可能會耗盡網站資源,盜取數據或利用安全漏洞。
有益機器人的特徵
-
robots.txt遵循: 大多數有益的機器人都會尊重網站的robots.txt文件,並遵循其中列出的規則(爬取允許/禁止區域、爬取速度等)。 -
正常的請求模式: 在請求之間保持適當的延遲,不會對伺服器造成過大負擔。
-
正式的
User-Agent: 使用清晰且已知的User-Agent字串,通常包含機器人擁有者的資訊(例如:Googlebot/2.1 (+http://www.google.com/bot.html))。 -
真實IP地址: 請求來自機器人擁有者的實際IP地址範圍。(例如:Googlebot使用Google擁有的IP範圍)
有害機器人的特徵
-
robots.txt忽略: 無視robots.txt文件,試圖未經授權訪問被禁止的區域。 -
不正常的請求模式: 在短時間內對特定頁面進行重複請求(DDoS攻擊嘗試)、異常快速的爬取速度等,導致伺服器過載。
-
偽造的
User-Agent: 偽裝成有益機器人(例如:Googlebot)的User-Agent,或使用隨機生成的User-Agent。 -
未知IP地址: 通過代理伺服器、VPN或殭屍計算機隱藏或頻繁更改IP地址。
-
惡意活動:
-
內容抓取(Content Scraping): 未經授權複製網站內容並在其他網站上發布或轉售。
-
庫存偷取(Inventory Sniping): 快速掌握電子商務網站上的產品庫存並惡意利用。
-
憑證填塞(Credential Stuffing): 使用盜取的用戶帳戶信息嘗試登錄其他網站。
-
垃圾郵件註冊: 自動在論壇或評論部分張貼垃圾內容。
-
DDoS攻擊: 生成大量流量使網站癱瘓。
-
漏洞掃描: 自動掃描網站的已知安全漏洞以尋找攻擊點。
-
有效阻止惡性機器人的方法
惡意機器人會無視如robots.txt的規則,假裝成真正用戶進入網站。因此,為了阻止它們,需要檢測到它們不正常的行為模式並對該請求進行選擇性阻止的高級策略。
1. 基於IP地址和User-Agent的阻攔(初步防線)
當惡意流量來自特定IP地址或IP範圍持續發生,或者使用明顯有害的User-Agent字串時可以暫時有效。
-
網頁伺服器設置(Apache、Nginx):
- 阻止某特定IP地址:
# Nginx 示例
deny 192.168.1.100;
deny 10.0.0.0/8;
- **阻止有害的 `User-Agent` :**
# Apache .htaccess 示例
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} "BadBotString|AnotherBadBot" [NC]
RewriteRule .* - [F,L] # 返回 403 Forbidden
局限性: IP 地址是動態的,並且可以通過代理、VPN、Tor網路輕易繞過。惡意機器人可能會無限變換IP,因此基於IP的阻止會增加管理負擔,難以成為長期解決方案。User-Agent也可以輕易被偽造,因此這種方法無法有效阻止精巧的惡意機器人。
2. 請求速率限制(Rate Limiting)
當對特定IP地址、User-Agent或特定URL的請求數量在短時間內異常急劇增加時,限制或阻止該請求。這對於防止DDoS攻擊或過度爬取的嘗試很有效。
- 網頁伺服器設置(Nginx 示例):
# 在 Nginx http 區塊內
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=5r/s;
# 在 server 或 location 區塊內
location / {
limit_req zone=mylimit burst=10 nodelay; # 允許每秒5個請求,最多突發10個
# ...
}
難度與風險:請求速率限制非常有用,但設置適當的閾值非常棘手。設置過於嚴格可能會限制正常用戶或有益的搜索引擎機器人流量,降低服務可達性。相反,設定過於寬鬆可能會讓惡意機器人達成目的。這需要建立在對服務特性和常規流量模式的深入理解之上,並需要持續的監測和調整。
3. 行為基礎檢測和定制防禦系統建立(最有效策略)
這是最精巧和有效的方法。惡意機器人可以隱藏其IP或User-Agent,但它們在網站內的行為模式通常會產生特異性。分析這些不正常的行為以識別惡意機器人,並建立針對該模式的防禦系統是關鍵。
-
流量監控和日誌分析的重要性:
網站伺服器日誌(Access Log)是了解機器人行為的最重要數據來源。定期(每天至少一次)檢閱和分析日誌是必不可少的。通過日誌分析,可以發現以下惡意機器人的不正常行為:
-
異常瀏覽路徑: 人類通常不會訪問的頁面順序、異常快速的頁面切換、對特定頁面的重複訪問。
-
重複特定操作的嘗試: 重複登錄失敗、嘗試使用不存在的賬號登錄、無限提交特定表單、使用宏在預約系統中占位。
-
可疑的URL請求: 對網站不存在的已知漏洞路徑(例如:
/wp-admin/,/phpmyadmin/,.env文件等)的重複訪問嘗試。 -
HTTP標頭分析: 異常的HTTP標頭組合或順序、標頭遺漏等。
-
-
惡意機器人行為模式示例:
應該識別在日誌中發現的惡意機器人的具體行為模式,並根據這些模式實現防禦邏輯。
-
GET /cgi-bin/luci/;stok=.../shell?cmd=RCE- 描述: 對
OpenWrt管理面板的遠程代碼執行(RCE)漏洞的攻擊嘗試,通常針對使用的嵌入式設備或路由器等基於Linux的系統。
- 描述: 對
-
POST /wp-login.php(重複登錄嘗試)- 描述: 對WordPress管理頁面的暴力破解攻擊或憑證填塞嘗試。
-
GET /HNAP1/- 描述: 對D-Link路由器上發現的HNAP1(家庭網絡管理協議)漏洞的掃描和攻擊嘗試。
-
GET /boaform/admin/formLogin- 描述: 嘗試侵入用於舊路由器或網絡攝像頭等設備的
Boa網頁伺服器的管理登錄頁面。
- 描述: 嘗試侵入用於舊路由器或網絡攝像頭等設備的
-
GET /.env或GET /.git/config- 描述: 透過訪問
.env文件(環境變量)或.git目錄來盜取敏感資訊的嘗試。
- 描述: 透過訪問
檢測到這些模式後,可以採取阻止該請求的措施,或者將IP暫時添加到黑名單中。這可以通過伺服器端的中介(例如Django中介)或網頁伺服器設置(Nginx
map模組、Apachemod_rewrite等)實現。 -
-
檢查JavaScript執行:
大多數惡意機器人無法像真正的瀏覽器那樣完全執行JavaScript。通過隱藏的JavaScript代碼(例如:誘導點擊特定DOM元素)、canvas指紋識別或調用瀏覽器API等,來判別是否為機器人,並阻止那些無法執行JavaScript的客戶端。
4. 使用Honeypot(陷阱)
Honeypot(蜜罐)是旨在誘導和識別惡意機器人的故意“陷阱”。這些元素對於正常用戶不可見,但設計用以被自動化機器人探索或互動。
-
工作原理:
-
隱藏的鏈接/字段: 利用CSS(
display: none;、visibility: hidden;、height: 0;等)或通過JavaScript動態生成然後移至畫面之外,創建對用戶完全不可見的鏈接或表單字段。 -
誘導機器人行為: 使用正常網頁瀏覽器的用戶看不到這些元素,因此無法與之互動。然而,機械地解析網頁上所有鏈接或表單的惡意機器人會發現這些隱藏的元素並嘗試互動(例如:在隱藏的表單字段中輸入值或點擊隱藏鏈接)。
-
識別惡意機器人: 當隱藏字段被填寫或有請求發生時,可以明確視作惡意機器人的行為。
-
自動阻止: 檢測到此行為的IP地址或會話會立即被加入黑名單或阻止。
-
-
實現示例:
<form action="/submit" method="post">
<label for="username">用戶名:</label>
<input type="text" id="username" name="username">
<div style="position: absolute; left: -9999px;">
<label for="email_hp">請留空此字段:</label>
<input type="text" id="email_hp" name="email_hp">
</div>
<label for="password">密碼:</label>
<input type="password" id="password" name="password">
<button type="submit">登錄</button>
</form>
伺服器將會檢測到 `email_hp` 字段是否有值,若有則判斷該請求為機器人並阻止。
- 優點: 可以在不干擾用戶體驗的情況下,有效識別惡意機器人。實現相對簡單,且不易被偽造。
5. 網頁應用防火牆(WAF)和專業機器人管理解決方案
如果運行大型網站或敏感服務,使用專業的WAF解決方案(Cloudflare、AWS WAF、Sucuri等)或機器人管理解決方案(Cloudflare Bot Management、Akamai Bot Manager、PerimeterX等)是最有效的。這些解決方案:
-
高級行為分析: 基於機器學習實時分析流量,偵測人類與機器人之間的微妙行為差異。
-
威脅情報: 利用全球攻擊模式和IP黑名單數據庫來識別各種威脅。
-
最小化誤封: 透過精細的演算法最小化對有益機器人及正常用戶的誤封,只篩選出惡意機器人。
-
自動化應對: 對偵測到的惡意機器人自動進行阻止及挑戰等措施。
結論:主動和多層的機器人防禦策略
惡意機器人不斷進化並試圖攻擊網站。robots.txt 只是對誠實爬蟲的指導,而無法作為阻擋入侵者的盾牌。因此,為了保護網站的安全與穩定,分析和識別機器人的行為,並有選擇性地阻止惡意機器人的主動和多層防禦策略如同關鍵。
通過日誌分析來模式化異常行為,精細化請求速率限制、使用Honeypot設置陷阱,必要時採用專業機器人管理解決方案或WAF,可以更安全地保護網站,並保持與有益機器人的順暢互動,為用戶提供良好的服務。那麼,你的網站對哪些機器人威脅最脆弱呢?是時候思考合適的防禦策略了。


目前沒有評論。