
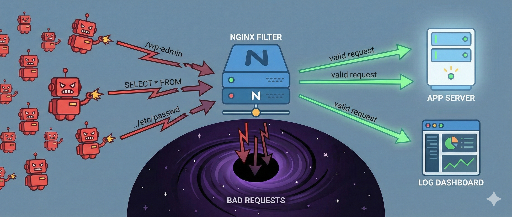
互联网是一个不断变化和扩展的巨大信息海洋。扮演着探索和收集这些庞大数据的重要角色的便是 网络爬虫(Web Crawler),通常称为 机器人(Bot) 的自动化程序。这些机器人在网络上游荡,索引信息、收集数据并提供多种服务,成为网络生态系统的重要组成部分。然而,并非所有机器人都是对网络有益的。有时,也存在有害的机器人,它们可能会对网站造成伤害或被恶意使用。
在本文中,我们将探讨在网络中常见的著名机器人的种类和特征,区分有益机器人和有害机器人的方法,以及 保护网站不受有害机器人侵害的有效方法。
网络中常见的著名机器人(有益机器人)
大多数网络流量是由机器人而非人类产生的。其中最重要和有益的机器人如下:
1. 搜索引擎机器人(Search Engine Bots)
最常见和重要的机器人。它们通过浏览网页来收集内容,并将其添加到搜索引擎索引中,以帮助用户查找信息。
-
Googlebot(谷歌): 谷歌的代表性网络爬虫。它浏览几乎所有网页,以更新搜索结果,并为谷歌服务(地图、新闻等)提供数据。
User-Agent中显示为Googlebot或Mediapartners-Google等。 -
Bingbot(微软必应): 微软的 Bing 搜索引擎爬虫。
User-Agent显示为Bingbot。 -
Baidu Spider(百度): 中国主要搜索引擎百度的爬虫。如果针对中国市场,Baidu Spider 的访问也很重要。
User-Agent显示为Baiduspider。 -
Yandex Bot(Yandex): 俄罗斯主要搜索引擎 Yandex 的爬虫。
User-Agent显示为YandexBot。 -
Yeti(Naver): 韩国 Naver 的代表性搜索引擎爬虫。它专门收集针对韩国市场的搜索结果,
User-Agent显示为Yeti。
2. 社交媒体机器人(Social Media Bots)
在社交媒体上分享链接时,生成该链接的预览(标题、描述、图像)时使用。
-
Facebook External Hit(Facebook): 当在 Facebook 上分享链接时获取页面信息。
User-Agent显示为facebookexternalhit。 -
Twitterbot(Twitter/X): 在 Twitter(X)中生成链接预览。
User-Agent显示为Twitterbot。 -
Slackbot(Slack): 在 Slack 中分享链接时生成预览。
User-Agent显示为Slackbot。
3. 监控/分析机器人(Monitoring/Analytics Bots)
用于监控网站状态、性能和安全漏洞,或进行流量分析。
-
UptimeRobot, Pingdom: 通过监控网站的正常运行时间,在网站停机时发送警报。
-
站点爬虫(Screaming Frog, Ahrefsbot, SemrushBot等): SEO 工具分析网站,寻找 SEO 改进点或收集竞争对手分析数据。
User-Agent中包含相应工具名称。 -
Ahrefsbot(Ahrefs): Ahrefs 是上述强大的 SEO 分析爬虫之一, Ahrefsbot 是网络上活动最频繁的商业爬虫。它收集有关网站的反向链接、关键词排名、自然流量等庞大的 SEO 数据,为 Ahrefs 服务用户提供。特别是,为了建立反向链接数据库,它在互联网上进行广泛的爬虫,因此在网站服务器日志中是仅次于
Googlebot的常见机器人之一。User-Agent显示为AhrefsBot。
区分有害机器人与有益机器人

机器人的流量对网站的影响主要取决于机器人的目的和行为方式。有害机器人可能会消耗网站资源、窃取数据或利用安全漏洞。
有益机器人的特征
-
遵守
robots.txt: 大多数有益机器人会尊重网站的robots.txt文件,并遵循其中的规则(允许/禁止爬虫的区域、爬虫速度等)。 -
正常的请求模式: 请求之间保持适当的延迟,不会给服务器带来过载。
-
正式的
User-Agent: 使用明确且知名的User-Agent字符串,通常包含机器人的所有者信息(例如:Googlebot/2.1 (+http://www.google.com/bot.html))。 -
真实的 IP 地址: 从该机器人所有者的真实 IP 地址范围内发送请求。(例如:Googlebot 使用谷歌拥有的 IP 段)
有害机器人的特征
-
忽视
robots.txt: 忽视robots.txt文件,试图未经授权访问被禁止的区域。 -
不正常的请求模式: 对特定页面的快速重复请求(DDoS 攻击尝试),爬虫速度异常快,给服务器带来过载。
-
伪造的
User-Agent: 伪装成有益机器人(例如 Googlebot)的User-Agent,或使用随机生成的User-Agent。 -
未知的 IP 地址: 通过代理服务器或 VPN、僵尸电脑等手段隐藏 IP 地址或频繁更换。
-
恶意活动:
-
内容抓取(Content Scraping): 未经授权复制网站内容,并在其他网站上发布或转售。
-
库存抢购(Inventory Sniping): 在电子商务网站快速识别商品库存,以便用于囤积等。
-
凭证填充(Credential Stuffing): 将窃取的用户账户信息输入到其他网站进行登录尝试。
-
垃圾注册: 自动在论坛或评论区发布垃圾内容。
-
DDoS 攻击: 产生大量流量使网站瘫痪。
-
漏洞扫描: 自动扫描网站已知的安全漏洞,以寻找攻击点。
-
有效阻止有害机器人的方法
恶意机器人会忽视像 robots.txt 这样的规则,伪装成真实用户侵入网站。因此,为了阻止它们,需要检测其异常行为模式,并采取选择性地阻止相关请求的高级策略。
1. 基于 IP 地址与 User-Agent 的阻止(初步防线)
当恶意流量持续来自特定 IP 地址或 IP 段,或使用明显有害的 User-Agent 字符串时,可以暂时采取措施。
-
WEB 服务器设置(Apache, Nginx):
- 阻止特定 IP 地址:
# Nginx 示例
deny 192.168.1.100;
deny 10.0.0.0/8;
- **阻止恶意 `User-Agent`:**
# Apache .htaccess 示例
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} "BadBotString|AnotherBadBot" [NC]
RewriteRule .* - [F,L] # 返回 403 Forbidden
局限性: IP 地址是 动态的或可通过代理、VPN、Tor 网络轻松绕过的。恶意机器人可以几乎无限地更改 IP,因此 基于 IP 的阻止可能只会增加管理负担,难以成为长期解决方案。 User-Agent 也很容易伪造,因此,仅凭这一方法难以阻止精巧的恶意机器人。
2. 请求速率限制(Rate Limiting)
当某个 IP 地址、User-Agent 或特定 URL 的请求数在短时间内异常激增时,限制或阻止该请求。这在防止 DDoS 攻击或过度抓取尝试时非常有效。
- WEB 服务器设置(Nginx 示例):
# Nginx http 块内
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=5r/s;
# server 或 location 块内
location / {
limit_req zone=mylimit burst=10 nodelay; # 每秒 5 个请求被允许,最大爆发 10 个
# ...
}
难度与风险: 请求速率限制非常有用,但 适当的阈值设置非常棘手。 如果设置得过于严格,将限制正常用户或有益搜索引擎机器人的流量,降低服务可达性。相反,如果设置得太宽松,将使恶意机器人达到其目的。这需要根据服务特性和正常流量模式深入理解,持续进行监控和调整。
3. 基于行为的检测与定制防御系统构建(最有效的策略)
这是最复杂和有效的方法。恶意机器人可以伪装 IP 或 User-Agent,但 它们在网站上的行为模式通常是特殊的。 识别这些异常行为并构建相应的防御系统是关键。
-
流量监控和日志分析的重要性:
WEB 服务器日志(Access Log)是识别机器人行为的最重要数据源。定期(每天至少一次)审查和分析日志是必不可少的。通过日志分析,能够发现以下恶意机器人的异常行为:
-
不正常的浏览路径: 一般人不会以此顺序访问的页面、不正常快速的页面移动、某个页面的重复访问。
-
重复的特定操作尝试: 登录失败頻繁、尝试用不存在的账户登录、重复不止提交特定表单、利用宏在预约系统中抢占座位。
-
可疑的 URL 请求: 对网站上不存在的已知漏洞路径(例如
/wp-admin/,/phpmyadmin/,.env文件)进行重复访问尝试。 -
HTTP 头分析: 不正常的 HTTP 头组合或顺序、头缺失等。
-
-
恶性机器人的行为模式化示例:
需识别日志中发现的恶意机器人的具体行为模式,并基于此实现防御逻辑。
-
GET /cgi-bin/luci/;stok=.../shell?cmd=RCE- 说明: 试图利用
OpenWrt管理面板的远程代码执行(RCE)漏洞。这通常针对在共享路由器或嵌入式设备上使用的 Linux 基于系统的漏洞。
- 说明: 试图利用
-
POST /wp-login.php(重复登录尝试)- 说明: 针对 WordPress 管理页面的暴力破解攻击或凭证填充尝试。
-
GET /HNAP1/- 说明: 利用曾在 D-Link 路由器上发现的 HNAP1(家庭网络管理协议)漏洞进行扫描和攻击尝试。
-
GET /boaform/admin/formLogin- 说明: 针对老旧路由器或摄像头等使用的
BoaWEB 服务器管理登录面板的入侵尝试。
- 说明: 针对老旧路由器或摄像头等使用的
-
GET /.env或GET /.git/config- 说明: 通过访问
.env文件(环境变量)或.git目录尝试窃取敏感信息。
- 说明: 通过访问
识别这些模式后,可以阻止相关请求或临时将 IP 添加到黑名单等措施。这可以通过服务器端的中间件(例如 Django 中间件)或 WEB 服务器设置(Nginx
map模块、Apachemod_rewrite等)实现。 -
-
检查 JavaScript 是否执行:
大多数恶意机器人不会像真实浏览器一样完美地执行 JavaScript。可以通过隐藏的 JavaScript 代码(例如:引导特定 DOM 元素的点击)、canvas 指纹识别或是否调用浏览器 API 来判断是否为机器人,并阻止执行 JavaScript 失败的客户端。
4. 利用蜜罐(Honeypot)
蜜罐(Honeypot) 是为引诱和识别恶意机器人而故意设计的“陷阱”。它在网页中隐藏着对正常用户不可见但旨在被自动化机器人探索或互动的元素。
-
工作原理:
-
隐藏链接/字段: 使用 CSS(
display: none;,visibility: hidden;,height: 0;等)或动态生成的 JavaScript 移动到屏幕外,创建对用户完全不可见的链接或表单字段。 -
促使机器人的行为: 使用正常的浏览器的人看不到这些元素,自然无法与之互动。但是,机械地解析页面上所有链接或表单的恶意机器人将发现并试图与这些隐藏元素互动(例如:在隐藏的表单字段中输入值或点击隐藏的链接)。
-
识别恶意机器人: 当隐藏字段被赋值或根据隐藏链接的请求发生时,可以明显判断这是恶意机器人的行为。
-
自动阻止: 当检测到这种行为的 IP 地址或会话时,可以立即将其加入黑名单或采取阻止措施。
-
-
实现示例:
<form action="/submit" method="post">
<label for="username">用户名:</label>
<input type="text" id="username" name="username">
<div style="position: absolute; left: -9999px;">
<label for="email_hp">此字段请留空:</label>
<input type="text" id="email_hp" name="email_hp">
</div>
<label for="password">密码:</label>
<input type="password" id="password" name="password">
<button type="submit">登录</button>
</form>
服务器将判断如果 `email_hp` 字段有值,则将该请求视为机器人并进行阻滞。
- 优点: 能够在不影响用户体验的情况下有效识别恶意机器人。相对较易实现,且不容易伪造。
5. WEB 应用防火墙(WAF)和专业机器人管理解决方案
如果运营大型网站或敏感服务,采用专业的 WAF 解决方案(Cloudflare、AWS WAF、Sucuri 等)或机器人管理解决方案(Cloudflare Bot Management、Akamai Bot Manager、PerimeterX等)是最有效的选择。这些解决方案:
-
高级行为分析: 基于机器学习实时分析流量,以检测人类和机器人的细微行为差异。
-
威胁情报: 利用全球攻击模式与 IP 黑名单数据库识别广泛的威胁。
-
减少误拦截: 通过精密算法最大程度地减少对有益机器人和正常用户的误拦截,只筛除恶意机器人。
-
自动化应对: 对检测到的恶意机器人进行自动阻止、提供挑战等措施。
结论:主动且多层次的机器人防御策略
恶意机器人不断进化,试图攻击网站。 robots.txt 只对诚实的机器人提供指导,而不能成为防御入侵者的屏障。因此,为了保障网站的安全与稳定, 分析并识别机器人的行为,建立主动且多层次的防御策略,只选择性地阻止恶意机器人是必不可少的。
通过日志分析发现异常行为模式、精细设置请求速率限制、利用蜜罐设置陷阱,以及必要时采用专业的机器人管理解决方案或 WAF,可以更安全地保护网站,同时与有益机器人保持良好互动,为用户提供优质服务。那么,您的网站最容易受到哪些机器人的威胁呢?是时候思考合适的防御策略了。


目前没有评论。