NumPy:深度学习初学者的必备工具——为什么先学它比先学 PyTorch 更重要
为什么深度学习初学者应该先学 NumPy?

在大多数深度学习书籍或课程中,PyTorch、TensorFlow 等框架往往是第一位出现的。然而,当你真正开始搭建模型时,往往会遇到以下困惑。
- “张量(tensor)到底是什么?”
- “形状不匹配,为什么会报错?”
- “我以为这样拼接批次就行了…?”
这些大部分混乱实际上是因为 在没有充分理解 NumPy 的情况下直接跳到深度学习框架 所导致的。
- PyTorch 的
Tensor与 NumPy 的ndarray概念几乎相同 - 数据预处理、批次生成、统计计算等仍然需要 NumPy 风格的思考
因此,如果你想真正掌握深度学习,NumPy 可以说是几乎不可或缺的基础体能。
NumPy 是什么?
NumPy(Numerical Python) 是一个帮助 Python 进行快速数值计算的库。
核心关键词总结:
- 多维数组(ndarray):向量、矩阵、张量表达的基础
- 向量化运算:无需
for循环即可一次性处理大量运算 - 广播(Broadcasting):即使形状不同的数组也能智能运算
- 线性代数运算:矩阵乘、转置、逆矩阵等
- 随机模块:数据采样、正态分布、随机初始化等
几乎所有深度学习中使用的公式都归结为 “向量与矩阵运算”,因此让你轻松处理这些运算的 NumPy 可以说是深度学习的语言。
Python 列表 vs NumPy 数组
先简单比较一下 Python 基础列表和 NumPy 数组的区别。
# Python 基础列表
a = [1, 2, 3, 4]
b = [10, 20, 30, 40]
# 列表相加
print(a + b)
# 结果: [1, 2, 3, 4, 10, 20, 30, 40] (拼接)
列表的 + 是 拼接 而不是 “逐元素相加”。
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([10, 20, 30, 40])
print(a + b)
# 结果: [11 22 33 44] (逐元素相加)
NumPy 数组的 + 是我们在数学中期望的 逐元素(element-wise)运算。深度学习框架的 Tensor 也 沿用 NumPy 的风格。
向量化:减少循环,像数学公式一样编码
在深度学习代码中,常常被告知要 最小化 for 循环。相反,使用 向量化(vectorization)。
举例:对所有元素求平方。
Python 列表 + for 循环
data = [1, 2, 3, 4, 5]
squared = []
for x in data:
squared.append(x ** 2)
print(squared) # [1, 4, 9, 16, 25]
NumPy 向量化
import numpy as np
data = np.array([1, 2, 3, 4, 5])
squared = data ** 2
print(squared) # [ 1 4 9 16 25]
- 代码更短
- 更 接近数学公式
- 内部使用 C 实现,性能更好
PyTorch、TensorFlow 的张量运算也同样使用 向量化的 NumPy 风格。
广播:形状不同也能一起运算
广播(broadcasting)是 不同尺寸数组自动匹配形状的规则。
举例:给每个样本加上相同的常数值。
import numpy as np
x = np.array([[1, 2, 3],
[4, 5, 6]]) # shape: (2, 3)
b = np.array([10, 20, 30]) # shape: (3,)
y = x + b
print(y)
# [[11 22 33]
# [14 25 36]]
x 是 (2, 3),b 是 (3,),NumPy 会把 b 视为 (1, 3) → (2, 3) 进行运算。
PyTorch 也同样适用:
import torch
x = torch.tensor([[1, 2, 3],
[4, 5, 6]])
b = torch.tensor([10, 20, 30])
y = x + b
print(y)
因此,掌握 NumPy 的广播规则,在 PyTorch 张量运算时会更自然。
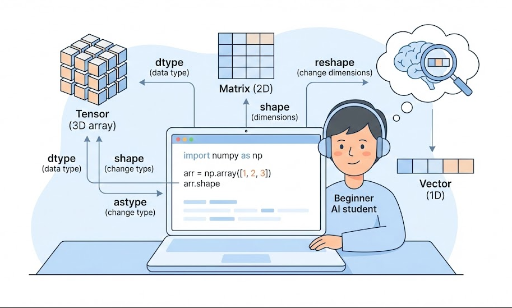
向量、矩阵、张量:用 NumPy 表达深度学习
在深度学习中常见的概念用 NumPy 表示:
- 向量(vector):1 维数组 →
shape: (N,) - 矩阵(matrix):2 维数组 →
shape: (M, N) -
张量(tensor):3 维及以上数组
-
例:图像批次
batch_size = 32,灰度 28x28 图像 →shape: (32, 28, 28)
举例:简单矩阵乘法
import numpy as np
# 输入向量(3 个特征)
x = np.array([1.0, 2.0, 3.0]) # shape: (3,)
# 权重矩阵(输入 3 → 输出 2)
W = np.array([[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6]]) # shape: (2, 3)
# 矩阵乘:y = W @ x
y = W @ x
print(y) # [1.4 3.2]
这段代码实际上相当于 单层线性层(linear layer) 的计算。 PyTorch 迁移后:
import torch
x = torch.tensor([1.0, 2.0, 3.0]) # shape: (3,)
W = torch.tensor([[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6]]) # shape: (2, 3)
y = W @ x
print(y)
形状与意义几乎相同。 熟悉 NumPy 矩阵运算 = 掌握深度学习公式。
NumPy 与 PyTorch 的连接方式
1. Tensor 与 ndarray 是“表兄弟”关系
- 两者都提供 n 维数组 + 向量化运算
shape、reshape、transpose、sum、mean等函数名与行为非常相似
因此,很多人把 NumPy 当作 练习 PyTorch 张量的练习场。
2. 数据预处理通常采用 NumPy 风格
深度学习项目中常见的工作:
- 读取 CSV、图像、日志等多种数据
- 转换为数值型
- 归一化、标准化、切片、打乱(shuffle)、分批
这些工作往往使用 NumPy + pandas 组合完成。
import numpy as np
import torch
# NumPy 中准备数据
np_data = np.random.randn(100, 3) # 100 个样本,3 个特征
# 转为 PyTorch 张量
tensor_data = torch.from_numpy(np_data).float()
print(tensor_data.shape) # torch.Size([100, 3])
反过来,把 PyTorch 张量再送回 NumPy 进行后处理也很常见。
y = tensor_data.mean(dim=0) # PyTorch 张量
y_np = y.detach().cpu().numpy()
也就是说,NumPy 与 PyTorch 在实际工作中是不断往来。
3. GPU 计算是 PyTorch,概念练习是 NumPy
- PyTorch 张量可以在 GPU(CUDA)上运行,并支持自动微分
- NumPy 基于 CPU,但 概念练习和调试更简单
因此,很多人会先用 NumPy 小规模实验想法或公式,验证后再迁移到 PyTorch 代码。
深度学习中常用的 NumPy 模式示例
1. 随机初始化 & 添加噪声
import numpy as np
# 权重初始化(正态分布)
W = np.random.randn(3, 3) * 0.01
# 给输入添加噪声
x = np.array([1.0, 2.0, 3.0])
noise = np.random.normal(0, 0.1, size=x.shape)
x_noisy = x + noise
2. 数据归一化(均值 0,标准差 1)
X = np.random.randn(100, 3) * 10 + 50 # 随机生成数据
mean = X.mean(axis=0) # 每个特征的均值
std = X.std(axis=0) # 每个特征的标准差
X_norm = (X - mean) / (std + 1e-8)
这种归一化在深度学习中对 性能和学习稳定性 有很大影响。
3. One-hot 编码
num_classes = 4
labels = np.array([0, 2, 1, 3]) # 4 个样本的类别索引
one_hot = np.eye(num_classes)[labels]
print(one_hot)
# [[1. 0. 0. 0.]
# [0. 0. 1. 0.]
# [0. 1. 0. 0.]
# [0. 0. 0. 1.]]
PyTorch 也以类似方式处理 one-hot。
4. 批次划分
X = np.random.randn(100, 3) # 100 个样本
batch_size = 16
for i in range(0, len(X), batch_size):
batch = X[i:i+batch_size]
# 这里可以想象把 batch 送进模型
这个模式与 PyTorch DataLoader 的概念直接对应。
学习 NumPy 时必须关注的要点
针对深度学习目标,不需要掌握所有功能。以下列表为核心,熟练掌握即可。
- ndarray 基础
*
np.array、dtype、shape、reshape、astype - 索引 & 切片
*
x[0]、x[1:3]、x[:, 0]、x[:, 1:3]* 布尔索引:x[x > 0] - 基本运算
*
+、-、*、/、**、比较运算 *np.sum、np.mean、np.max、np.min、axis概念 - 线性代数
* 矩阵乘:
@或np.dot* 转置:x.T - 广播
* 标量加/乘
*
(N, D) + (D,)、(N, 1)等模式 - 随机函数
*
np.random.randn、np.random.randint、np.random.permutation - PyTorch 关联
*
torch.from_numpy、tensor.numpy()* 观察shape的对应关系
掌握以上内容后,在 PyTorch 教程中出现的大多数张量运算都会更自然。
结语:NumPy 是“深度学习语法书”
总结:
- NumPy 是 数值计算的多维数组库
- PyTorch 的
Tensor实际上是 NumPyndarray的深度学习版 - 向量化、广播、线性代数 用 NumPy 学习后,
- 更少遇到 shape 错误
- 更容易把论文公式写成代码
- 数据预处理/分析能力同步提升
如果你想从 框架使用 转向 数学/数组运算视角,NumPy 是最好的起点。





目前没有评论。