python-magic: “de meest praktische manier om bestanden te identificeren op basis van inhoud in plaats van extensie”
Wanneer je een afbeelding-uploadfunctie op een server implementeert, ontstaat er op een gegeven moment de volgende vraag.
- “Het bestand is geüpload met de extensie
.png… is het echt een PNG?” - “Moet ik eerst bepalen of het een afbeelding of een document is?”
- “Voordat ik een externe parser (Pillow/OpenCV) gebruik, wil ik ten minste het type controleren.”
In dat geval is de beste startpunt niet de extensie, maar de inhoud van het bestand.
En het meest eenvoudige hulpmiddel om deze “inhoud gebaseerde identificatie” te verkrijgen is python-magic.
Wat doet python-magic?
python-magic is een wrapper die de C‑bibliotheek libmagic in Python beschikbaar maakt. Libmagic analyseert kenmerken zoals de header (de eerste paar bytes) van een bestand om het type te bepalen. Deze functionaliteit is ook beschikbaar via het Unix‑commando file.
Kort samengevat:
file(Linux‑commando) = “interface die je in de terminal gebruikt”libmagic= “kernmachine (identificatielogica)”python-magic= “lichte wrapper die libmagic in Python aanroept”
In dit artikel richten we ons op python-magic en leggen we op een gestructureerde manier uit hoe dit engine eigenlijk het bestandstype bepaalt.
Hoe werkt de kernmachine (libmagic)?
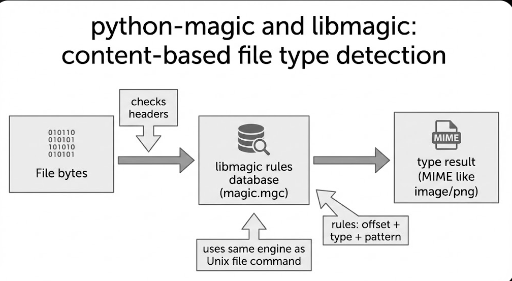
De essentie van libmagic is eenvoudig.
“Het leest een database met regels voor bestandsidentificatie, controleert de bytes van het bestand volgens die regels en trekt de meest waarschijnlijke conclusie.”
Hier is de database de magic database (magic pattern DB) en file/libmagic gebruiken deze samen. Meestal wordt het geïnstalleerd als een gecompileerde vorm (magic.mgc).
1) “Magic‑file” is een verzameling regels
Deze regels bestaan in principe uit de volgende componenten.
- Waar te kijken (offset: positie in het bestand)
- Hoe te lezen (type: byte/tekst/integers, etc.)
- Wat te vergelijken (expected value/pattern)
- Welke conclusie te trekken (message/MIME, etc.)
De handleiding van file beschrijft ook dat het “magic patterns” controleert. Deze regels worden regel voor regel getest (offset/type/waarde/bericht) en als de voorwaarde klopt, gaan ze dieper in een “hiërarchische” structuur met meer specifieke subtests.
Wil je meer weten over het file‑commando van Linux? Klik dan op de onderstaande link.
Meer over het Linux‑file‑commando
2) De regels‑database bestaat uit “tekst‑bron” en “gecompileerde resultaten”
De magic‑DB kan oorspronkelijk een verzameling leesbare tekstfragmenten zijn, maar voor prestaties wordt het vaak ook geleverd als een gecompileerde binaire DB (.mgc).
3) Uiteindelijk doet het “kijken naar de inhoud in plaats van de extensie”
file is al lang een “type‑schatter die de inhoud bekijkt in plaats van de extensie”. python-magic brengt die filosofie in één regel Python‑code.
Hoe gebruik je python-magic?
Er zijn twee typische gebruikspatronen.
1) Ontvang het MIME‑type (meest praktisch)
Handig voor upload‑verwerking, routing, logging/metrics.
import magic
mime = magic.from_file("upload.bin", mime=True)
print(mime) # bijvoorbeeld: image/png
python-magic biedt bestandsidentificatie op basis van libmagic, en dit staat ook in de officiële beschrijving.
2) Direct bytes‑identificatie (handig voor upload‑streams)
Voordat je het bestand op de schijf opslaat, wil je vaak een snelle identificatie op basis van een deel van de geüploade bytes.
import magic
with open("upload.bin", "rb") as f:
head = f.read(4096)
mime = magic.from_buffer(head, mime=True)
print(mime)
(Buffer‑gebaseerde identificatie is vooral goed als “eerste filter vóór het opslaan”.)
Waar is het nuttig vanuit een ontwikkelaarsperspectief?
1) Eerste verdedigingslinie voor upload‑verificatie
- Niet alleen op extensie vertrouwen
- Ten minste bevestigen of het bestand als afbeelding kan worden verwerkt
2) Splitsingspunt in de verwerkingspipeline
- Als afbeelding: doorgaan naar resize/thumbnail‑pipeline
- PDF/ZIP: naar een andere worker
- Onbekend type: isoleren/weigeren/extra verificatie
3) Kosten verlagen vóór het aanroepen van “zware decoders”
Pillow en andere decoders zijn krachtig, maar het aanroepen ervan brengt kosten (geheugen/CPU/aanvalsoppervlak) met zich mee. python-magic is ideaal om eerst te bepalen of het de moeite waard is.
Belangrijk realistisch punt: libmagic is een schatting/identificatie‑tool. Voor volledige beveiliging (malware‑blokkering, etc.) zijn aanvullende controles nodig (whitelisting, grootte‑limieten, sandbox‑decodering, etc.).
Afsluiting: python-magic is de lichtste manier om bestandsidentificatie in code te brengen
python-magic levert niet de afbeeldingverwerking zelf.
Het geeft je in plaats daarvan snel aan hoe je het bestand moet behandelen.
- Engine:
file‑achtige libmagic - Identificatiemethode: “regels‑DB + byte‑controle”
- Praktisch in de ontwikkelomgeving voor upload‑verificatie, routing en kostenreductie
Door dit te leren, kun je zelfs in omgevingen zonder uitgebreide bibliotheken een identificatie → routing → beveiligingsmaatregel‑keten opzetten.
Vooruitblik op het volgende artikel
- Wat garanderen
open(),load()enverify()van Pillow (PIL) en wanneer je welke methode moet gebruiken, en hoe ze werken.
Gerelateerde artikelen