nginx로 시작하는 실전 로드밸런싱 가이드
많은 개발자가 nginx를 “리버스 프록시 + 정적 파일 서버” 정도로만 쓰지만, 사실 nginx는 꽤 강력한 소프트웨어 로드밸런서입니다. 직접 서버도 관리하는 개발자라면, nginx만 잘 써도 트래픽이 몰릴 때 서비스 안정성과 성능을 꽤 크게 끌어올릴 수 있습니다.
이 글에서는 초보–중급 개발자 기준으로:
- 로드밸런싱 개념
- nginx 로드밸런싱 설정 방법
- 알고리즘(라운드 로빈, least_conn, ip_hash 등)
- 건강 상태 체크(헬스 체크)
- 자주 쓰는 옵션들
까지 한 번에 정리해 보겠습니다.
1. 로드밸런싱이란 무엇인가?

로드밸런싱(load balancing) 은 간단히 말해,
“여러 대의 서버에 요청을 골고루 분산해서 한 대에 과부하가 걸리지 않게 해주는 것”
입니다.
왜 필요한가?
- 트래픽 폭주 대비
-
특정 시간에 요청이 몰려도 한 서버가 죽지 않도록. 2. 확장성(스케일 아웃)
-
서버를 세로로(스펙 업) 키우는 대신, 여러 대를 가로로 늘려서 처리량을 올림. 3. 장애 허용(고가용성)
-
한 서버가 죽어도 다른 서버로 트래픽을 보내 서비스 유지.
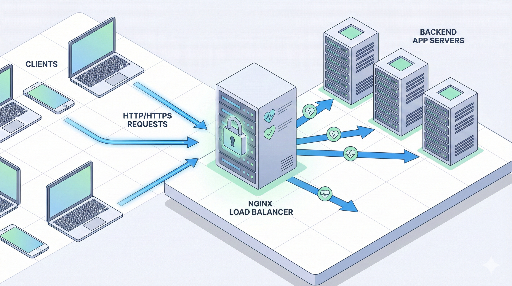
nginx는 어디에 서 있을까?
보통 구조는 이렇게 됩니다:
클라이언트 → nginx (로드밸런서 / 리버스 프록시) → 여러 대의 앱 서버
여기서 nginx가 요청을 받아서, 뒤에 있는 여러 앱 서버 중 하나로 보내주는 역할을 합니다.
2. nginx 로드밸런싱 기본 구조 이해하기
nginx 설정에서 로드밸런싱의 핵심은 크게 두 부분입니다.
- upstream 블록:
- “백엔드 서버 풀” 정의
- server / location 블록:
- 들어오는 요청을 어떤 upstream으로 보낼지 정의
가장 단순한 예제를 먼저 보겠습니다.
http {
upstream app_backend {
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://app_backend;
# 프록시 기본 헤더들
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
이 설정이 의미하는 것
-
upstream app_backend -
10.0.0.101:3000,10.0.0.102:3000두 대의 앱 서버를 하나의 풀로 묶음 -
proxy_pass http://app_backend; -
클라이언트 요청을
app_backend풀 중 한 서버로 전달 - 로드밸런싱 방법(알고리즘)은 따로 안 쓰면 기본은 라운드 로빈(round robin) 입니다.
3. 로드밸런싱 알고리즘 종류
nginx는 여러 가지 분산 전략을 제공합니다. 상황에 맞게 선택하는 것이 중요합니다.
3.1 기본: 라운드 로빈 (round robin)
설정: 아무것도 안 쓰면 기본
upstream app_backend {
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
- 첫 번째 요청 → 서버1
- 두 번째 요청 → 서버2
- 세 번째 요청 → 다시 서버1 …
장점: 단순하고 대부분의 경우 무난하게 사용 가능 단점: 각 서버의 현재 부하 상황은 고려하지 않음
3.2 least_conn (현재 연결이 가장 적은 서버로)
upstream app_backend {
least_conn;
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
- 활성 연결 수가 가장 적은 서버로 새 요청을 보냄
- 요청 처리 시간이 서버마다 차이가 큰 서비스(예: 일부 요청이 오래 걸리는 API)에 유리
추천 사용 시나리오
- 특정 요청은 오래 걸리고, 어떤 요청은 금방 끝나는 API 서버
- 서버 스펙은 비슷하지만, 요청 패턴이 불균일한 경우
3.3 ip_hash (같은 클라이언트 → 같은 서버로)
upstream app_backend {
ip_hash;
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
- 클라이언트 IP를 해시해서 항상 같은 서버로 라우팅
- 세션 스티키(sticky session) 가 필요한 경우에 간단히 사용 가능 (세션을 서버 메모리에 저장하고 있는 레거시 구조에서 자주 사용)
장점
- 사용자 세션이 서버 메모리에 있어도, 동일 사용자 요청이 같은 서버로 감
단점
- 서버를 추가/제거하면 해시가 뒤틀려서 많은 사용자의 매핑이 바뀔 수 있음
- 사용자의 실제 요청이 프록시 뒤에 있는 경우(예: Cloudflare, ELB 등) 진짜 클라이언트 IP를 못 받으면 의미가 없음
3.4 가중치(weight) 기반 분산
서버마다 스펙이 다를 때, 더 좋은 서버에 더 많은 트래픽을 보내고 싶을 수 있습니다.
upstream app_backend {
server 10.0.0.101:3000 weight=3;
server 10.0.0.102:3000 weight=1;
}
- 서버1 : 서버2 = 3 : 1 비율로 요청 분배
- 스펙 좋은 신규 서버를 우선적으로 활용할 때 유용
4. 헬스 체크(Health Check)와 장애 서버 처리
로드밸런서가 진짜로 “똑똑해지려면”, 죽은 서버를 자동으로 빼주는 기능이 중요합니다.
nginx 오픈소스 버전에서는 기본적으로 패시브 헬스 체크(passive health check)를 지원합니다.
4.1 max_fails / fail_timeout
upstream app_backend {
server 10.0.0.101:3000 max_fails=3 fail_timeout=30s;
server 10.0.0.102:3000 max_fails=3 fail_timeout=30s;
}
-
max_fails=3 -
연속해서 3번 실패하면 해당 서버를 비정상으로 간주
-
fail_timeout=30s -
30초 동안은 해당 서버로 트래픽을 보내지 않음
- 이후 다시 요청을 보내보고, 살아 있으면 다시 사용
여기서 “실패”의 기준은 주로 502/503/504 응답, 연결 실패 등입니다.
4.2 proxy_next_upstream
어떤 상황에서 다음 서버로 요청을 넘길지 정할 수 있습니다.
location / {
proxy_pass http://app_backend;
proxy_next_upstream error timeout http_502 http_503 http_504;
}
- 지정된 오류가 발생하면, 다음 서버로 재시도
- 과도한 재시도는 지연을 늘릴 수 있으니 필요한 케이스만 명시하는 것이 좋습니다.
5. 실전 설정 예제: 간단한 웹 서비스 로드밸런싱
예를 들어, Node.js 앱 서버 두 대를 3000번 포트에서 띄운 상태라고 가정해 봅시다.
10.0.0.101:300010.0.0.102:3000
5.1 nginx 설정 예제
http {
upstream app_backend {
least_conn;
server 10.0.0.101:3000 max_fails=3 fail_timeout=30s;
server 10.0.0.102:3000 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
server_name myservice.com;
# 클라이언트 → nginx → Node.js 서버로 프록시
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_read_timeout 60s;
proxy_connect_timeout 5s;
proxy_send_timeout 10s;
}
}
}
이렇게 설정하고 nginx를 리로드하면:
myservice.com으로 들어오는 모든 요청은 → nginx가 받고 → 현재 연결이 적은 Node.js 서버로 전달- 특정 서버가 여러 번 연속 실패하면 → 일정 시간 동안은 자동으로 대상에서 제외
6. HTTPS(SSL) 종료 + 로드밸런싱
프로덕션 환경에서는 거의 항상 HTTPS를 사용합니다. nginx를 SSL 종료(termination) 지점으로 쓰는 패턴이 가장 일반적입니다.
http {
upstream app_backend {
least_conn;
server 10.0.0.101:3000;
server 10.0.0.102:3000;
}
server {
listen 443 ssl;
server_name myservice.com;
ssl_certificate /etc/letsencrypt/live/myservice.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/myservice.com/privkey.pem;
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
# HTTP → HTTPS 리다이렉트
server {
listen 80;
server_name myservice.com;
return 301 https://$host$request_uri;
}
}
- 클라이언트와 nginx 사이: HTTPS
- nginx와 앱 서버 사이: HTTP (내부망이면 보통 이렇게 사용)
7. 세션 문제: 스티키 세션이 꼭 필요할까?
예전에는 서버 메모리에 세션을 저장하는 경우가 많아서, 같은 사용자는 같은 서버로 보내야 하는 요구가 많았습니다.
이때 nginx에서는 ip_hash로 간단히 해결할 수 있지만,
요즘은 보통 아래 중 하나를 많이 씁니다.
- Redis 등 외부 스토리지에 세션 저장
- JWT 기반으로 서버 stateless하게 구성
가능하다면 애플리케이션 레벨에서 상태를 제거하고, 로드밸런서는 순수하게 트래픽 분산만 하도록 하는 것이 운영과 확장에 훨씬 유리합니다.
8. 자주 쓰는 튜닝 포인트
8.1 keepalive 설정
백엔드 서버와의 연결을 재사용하면 성능에 도움이 됩니다.
upstream app_backend {
least_conn;
server 10.0.0.101:3000;
server 10.0.0.102:3000;
keepalive 32;
}
server {
location / {
proxy_pass http://app_backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
-
keepalive 32; -
각 워커 프로세스에서 백엔드로 최대 32개의 keepalive 연결 유지
- 매 요청마다 TCP 연결을 새로 맺지 않아서 레이턴시와 부하가 줄어듦
8.2 버퍼 & 타임아웃
응답이 큰 경우, 혹은 백엔드가 느린 경우 버퍼 및 타임아웃 설정도 중요합니다.
location / {
proxy_pass http://app_backend;
proxy_buffering on;
proxy_buffers 16 16k;
proxy_busy_buffers_size 64k;
proxy_read_timeout 60s;
proxy_send_timeout 60s;
}
proxy_read_timeout이 너무 짧으면 → 백엔드가 조금만 느려도 504 에러(게이트웨이 타임아웃) 발생 가능- 실제 트래픽 패턴과 백엔드 성능에 맞게 조정 필요
9. nginx 로드밸런싱 도입 전략 (단계별)
이미 서비스가 돌아가고 있고, 한 대의 서버에 모든 걸 올려둔 상태라면 아래처럼 단계적으로 확장하는 방법을 추천합니다.
- 1단계: nginx를 리버스 프록시로 먼저 도입
- 클라이언트 → nginx → 기존 단일 앱 서버
- SSL 종료, 캐싱, 정적 파일 서빙부터 활용
- 2단계: 앱 서버 복제 후 upstream 구성
- 기존 서버를 복제하거나 새 서버를 올려 기능/데이터 동기화
upstream블록에 두 서버를 넣고 로드밸런싱 시작
- 3단계: 헬스 체크 + 모니터링
max_fails,fail_timeout,proxy_next_upstream설정- 로그/메트릭 수집 도입 (예: Prometheus + Grafana, ELK 등)
- 4단계: 알고리즘 및 세부 튜닝
- 트래픽 패턴에 따라
least_conn또는weight활용 - keepalive, 버퍼 및 타임아웃 등 통해 성능 개선
마무리
nginx를 “그냥 리버스 프록시”로만 쓰기에는 아까울 정도로, 로드밸런싱 기능이 잘 갖춰져 있습니다.
- upstream 블록으로 서버 풀 정의
- 상황에 맞는 로드밸런싱 알고리즘 선택 (round robin / least_conn / ip_hash / weight)
- 헬스 체크 + 재시도 정책으로 장애 서버 자동 제외
- HTTPS 종료 + 백엔드 프록시 구조로 보안과 성능을 동시에
까지 이해하고 나면, “트래픽이 좀 늘어나는데 서버 한 대로 괜찮을까?”라는 고민이 들 때 nginx로 한 단계 업그레이드된 인프라를 직접 구성할 수 있게 됩니다.


댓글이 없습니다.